连路追踪 / 性能监测
全连路追踪
skywalking
这里使用探针实现信息收集,使用默认的 H2 存储
springboot 配置
server:
port: 8848
spring:
datasource:
url: jdbc:mysql://mysql:3306/dev?serverTimezone=UTC&useSSL=false&autoReconnect=true&tinyInt1isBit=false&useUnicode=true&characterEncoding=utf8&allowPublicKeyRetrieval=true
username: admin
password: admin
jpa:
properties:
hibernate:
format_sql: true
hbm2ddl:
auto: update
redis:
host: redis
port: 6379
pool:
max-active: 8
max-wait: -1
max-idle: 4
min-idle: 1
Dockerfile 配置
-
ADD /target/decsion-engine-0.1.5.jar app.jar- 拷贝项目打包好的 jar 包
-
ADD ./agent agent- 注意:agent 需要和 jar 包放一起,不仅仅是 skywalking-agent.jar,
- config 下是 skywalking 的默认配置文件,其中的参数可以被 java 传递的参数覆盖
- log 下存储了日志,一般监测信息没有可以尝试查看该文件夹
- plugin 下存储了对不同进程的信息采集工具,必须依赖他们才能正常监测
-
java xxx- xxx 指服务的名字,随意
- backend_service 指的是 skywalking 的链接
- 可以是 docker-compose 定义的 (oap:port1)
- 也可以是宿主机的 ip 端口 (192.168.xxx:port2)
-
完整
FROM adoptopenjdk/openjdk8
VOLUME ["/tmp", "/logs"]
EXPOSE 8848
ADD /target/decsion-engine-0.1.5.jar app.jar
ADD ./agent agent
# ADD ./skywalking-agent.jar skywalking-agent.jar # 这个不对
CMD java -javaagent:agent/skywalking-agent.jar -Dskywalking.agent.service_name=xxx -Dskywalking.collector.backend_service=192.168.31.226:11800 -jar app.jar
# 下面的一样,不影响,如果没成功,一定是别的地方写错了😅
# ENTRYPOINT ["java", "-javaagent:agent/skywalking-agent.jar", "-Dskywalking.agent.service_name=xxx", "-Dskywalking.collector.backend_service=192.168.31.226:11800", "-jar", "app.jar"]
docker-compose.yml
需要注意的点
- 服务的先后顺序
- 通过设置 restart 不断重试,直到依赖的服务启动完成
- ip(host), 端口号 (port)
- 容器之间通过可以直接用
${container_name}:${container_port}互相访问:mysql:3306 - 也可以直接用
${host_ip}:${host_port}互相访问:192.168.31.226:4205
- 容器之间通过可以直接用
services:
web:
# image: "trdthg/decision-engine:latest"
build: .
ports:
- "8848:8848"
depends_on:
- mysql
- redis
- oap
- skywaling-ui
restart: always
mysql:
image: mysql:latest
environment:
MYSQL_DATABASE: dev
MYSQL_USER: admin
MYSQL_PASSWORD: admin
MYSQL_ROOT_PASSWORD: 2022A22db
ports:
- "4205:3306"
logging:
driver: "none"
restart: always
redis:
image: "redis:alpine"
ports:
- "5470:6379"
logging:
driver: "none"
oap:
image: apache/skywalking-oap-server:8.4.0-es6
container_name: oap
restart: always
ports:
- 11800:11800 # agent 上报数据的端口,这是 gRPC 端口
- 12800:12800 # ui 读取数据的端口,这是 http 端口
# logging:
# driver: "none"
skywaling-ui:
image: apache/skywalking-ui:8.4.0
container_name: ui
depends_on:
- oap
links:
- oap
ports:
- 8088:8080
environment:
- SW_OAP_ADDRESS=http://oap:12800
logging:
driver: "none"
参考
火焰图
火焰图简明教程
arthas
arthas 是 Alibaba 开源的 Java 诊断工具,其中整合了很多实用的工具,例如查看当前 JVM 的线程堆栈信息、查看和修改 JVM 的系统属性、方法执行数据观测、生成火焰图等。最大的优点是对监控应用无代码侵入,也不需要重启监控应用或者添加启动参数就可以随意 attach 到目标 JVM 进程然后进行各种操作。 此处重点提到的是 arthas 中的 profiler 功能,实际上是对 async-profiler 的封装,可以对 JVM 应用进行采样后输出各种类型的火焰图。
基本使用
1. 安装启动
启动 profiler 采样后,需要选择对应的进程
wget https://alibaba.github.io/arthas/arthas-boot.jar
java -jar arthas-boot.jar
2. 开始采集
2.1 基于 CPU 使用率采样 (适用于 CPU 密集型)
async-profiler 支持对多种事件做采样分析,例如 cpu、alloc、lock、cache-misses 等,常用的采样事件为 cpu 和 wall。其中火焰图采样未指定事件时默认对 cpu 事件进行采样,即 On-CPU 火焰图,仅包含 JVM 在 CPU 执行时的采样,而不包含 CPU 等待时的采样。
$ profiler start
Started [cpu] profiling
2.2 基于样本采样,可估算耗时 (适用于 IO 密集型)
如果需要分析 IO 密集型应用,比较适合对 wall 事件进行采样,如下官方描述,wall 事件会对所有任意状态的线程进行采样,既包含 CPU 执行时的采样,也包含了 CPU 等待时的采样,可以用来更显著地分析线程在各个方法上的耗时分布。
$ profiler start -e wall
Started [wall] profiling
3. 查看状态
获取已采集的 sample 的数量
$ profiler getSamples
查看 profiler 状态
$ profiler status
[cpu] profiling is running for 4 seconds
4. 生成结果
生成 svg 格式结果
$ profiler stop --file xxx.svg --format svg
profiler output file: /tmp/demo/arthas-output/20191125-135546.svg
OK
5. demo
@RestController
@RequestMapping
public class IndexController {@GetMapping("/")
public String index() throws InterruptedException {
long start = System.currentTimeMillis();
cpuHandler();
long time1 = System.currentTimeMillis();
timeHandler();
long time2 = System.currentTimeMillis();
normalHandler();
long time3 = System.currentTimeMillis();
return String.format("%d %d %d", time1 - start, time2 - time1, time3 - time2);
}
private int cpuHandler() {
int value = 0;
int max = (int)(Math.random() * 100_000_000);
for (int i = 0; i < max; i++) {
value += i;
}
return value;
}
private void timeHandler() throws InterruptedException {
Thread.sleep(10);
}
private void normalHandler() {
Random random = new Random();
random.nextInt(100);
}
}
-
cpu 事件采样
由图可以明细的看出来,index 方法中 cpuHandler 事件采样占比最高,即 On-CPU 中 cpuHandler 方法占用的 CPU 最高。如果因为应用占用 CPU 消耗高,需要进行优化,那么通过该火焰图很容易分析出来需要对 cpuHandler 方法优化来降低 CPU 消耗。
-
wall 事件采样
由图可以明细的看出来,index 方法中 timeHandler 事件采样占比最高,即 timeHandler 方法占用线程耗时时间最高。如果因为 index 方法耗时较长,需要进行优化,那么通过该火焰图很容易分析出来需要对 timeHandler 方法优化来降低线程耗时时间
直接观察"平顶"(plateaus)往往不能快速定位性能问题,因为顶部记录的多半是对底层库函数的调用情况。我认为,要快速定位性能问题,首先应该观察的是业务函数在火焰图中的宽度,然后在往顶部找到第一个库函数来缩小范围,而不是直接就看平顶。
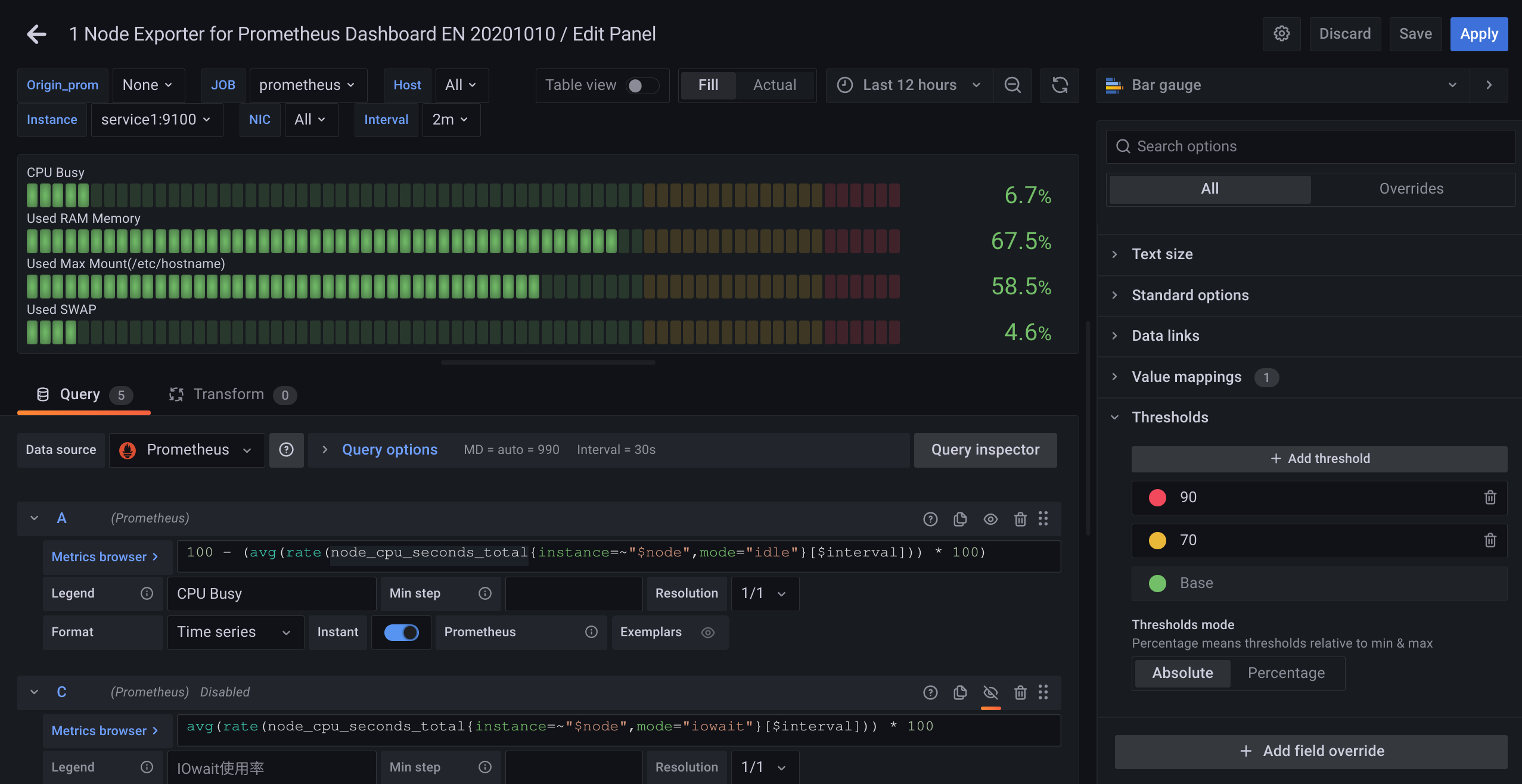
prometheus
被监控的进程需要向prometheus发送固定格式的信息,因为格式固定,可以根据prometheus的查询语句去筛选数据,并导出图标
PromQL
一条完整的查询语句主要有
- 匹配数据源
- 运算
- 函数 这三部分组成
- 查询内存占用
数据源:
# HELP node_memory_MemFree_bytes Memory information field MemFree_bytes.
# TYPE node_memory_MemFree_bytes gauge
node_memory_MemFree_bytes 4.85957632e+08
# HELP node_memory_MemTotal_bytes Memory information field MemTotal_bytes.
# TYPE node_memory_MemTotal_bytes gauge
node_memory_MemTotal_bytes 1.6170528768e+10
计算:(总内存 - 空闲内存) / 总内存 * 100
(
(
node_memory_MemTotal_bytes{instance="$node",job="$job"}
- node_memory_MemFree_bytes{instance="$node",job="$job"}
) / (node_memory_MemTotal_bytes{instance="$node",job="$job"} )) * 100
- 查询 cpu 总占用
各个内核的数据
# HELP node_cpu_seconds_total Seconds the CPUs spent in each mode.
# TYPE node_cpu_seconds_total counter
node_cpu_seconds_total{cpu="0",mode="idle"} 134248.98
node_cpu_seconds_total{cpu="0",mode="iowait"} 94.73
node_cpu_seconds_total{cpu="0",mode="irq"} 0
node_cpu_seconds_total{cpu="0",mode="nice"} 2.6
node_cpu_seconds_total{cpu="0",mode="softirq"} 4554.64
node_cpu_seconds_total{cpu="0",mode="steal"} 0
node_cpu_seconds_total{cpu="0",mode="system"} 3190.14
node_cpu_seconds_total{cpu="0",mode="user"} 6843.42
node_cpu_seconds_total{cpu="1",mode="idle"} 12962.19
node_cpu_seconds_total{cpu="1",mode="iowait"} 12.3
node_cpu_seconds_total{cpu="1",mode="irq"} 0
node_cpu_seconds_total{cpu="1",mode="nice"} 2.05
node_cpu_seconds_total{cpu="1",mode="softirq"} 464.51
node_cpu_seconds_total{cpu="1",mode="steal"} 0
node_cpu_seconds_total{cpu="1",mode="system"} 2174.27
node_cpu_seconds_total{cpu="1",mode="user"} 5931.27
node_cpu_seconds_total{cpu="10",mode="idle"} 12798.81
node_cpu_seconds_total{cpu="10",mode="iowait"} 16.9
node_cpu_seconds_total{cpu="10",mode="irq"} 0
node_cpu_seconds_total{cpu="10",mode="nice"} 2.27
node_cpu_seconds_total{cpu="10",mode="softirq"} 39.99
node_cpu_seconds_total{cpu="10",mode="steal"} 0
node_cpu_seconds_total{cpu="10",mode="system"} 2554.07
100 - (
# 取平均值
avg(
# rate 函数能够求 counter 类型数据的增长率,类似于加速度,能够反映变化的剧烈程度
rate(
# 只匹配 mode 为 idle 的行,
node_cpu_seconds_total{instance=~"$node",mode="idle"}[$interval])
) * 100
)
配置文件
global:
scrape_interval: 15s # 全局默认刷新时间
external_labels:
monitor: 'codelab-monitor'
scrape_configs:
- job_name: 'service1' # 一个 job 可以监控多个实例,实例可以分组
scrape_interval: 5s
static_configs:
# - targets: ['localhost:8080', 'localhost:8081']
# labels:
# group: 'production'
- targets: ["service1:9100"]
labels:
group: 'node'
- job_name: 'jmeter' # jmeter 运行过程中会在 9270 端口,可以监控
scrape_interval: 5s
static_configs:
- targets: ["jmeter:9270"]
labels:
group: 'jmeter'
监测 springboot
jmeter
运行测试
JVM_ARGS="-Xms1g -Xmx1g" jmeter.sh -n -t benchmark.jmx
参数
-n 命令行模式
-t 指定 jmx 脚本地址(地址可以是相对路径,可以是绝对路径)
-h 查看帮助
-v 查看版本
-p 指定读取 jmeter 属性文件,比如 jmeter.properties 文件中设置的
-l 记录测试结果的文件,通常结果文件为 jtl 格式(文件可以是相对路径,可以是绝对路径)
-s 以服务器方式运行(也是远程方式,启动 Agent)
-H 设置代理,一般填写代理 IP
-P 设置代理端口
-u 代理账号
-a 代理口令
-J 定义 jmeter 属性,等同于在 jmeter.properties 中进行设置
-G 定义 jmeter 全局属性,等同于在 Global.properties 中进行设置,线程间可以共享)
-D 定义系统属性,等同于在 system.properties 中进行设置
-S 加载系统属性文件,可以通过此参数指定加载一个系统属性文件,此文件可以用户自己定义
-L 定义 jmeter 日志级别,如 debug、info、error 等
-j 制定执行日志路径。(参数为日志路径,不存在不会自动创建,将日志输出到命行控制台)
-r 开启远程负载机,远程机器列表在 jmeter.properties 中指定
-R 开启远程负载机,可以指定负载机 IP,会覆盖 jmeter.properties 中 remote_hosts 的设置
-d 指定 Jmeter Home 目录
-X 停止远程执行
-g 指定测试结果文件路径,仅用于生成测试报表,参数是 csv 结果文件
-e 设置测试完成后生成测试报表
-o 指定测试报告生成文件夹(文件夹必须存在且为空文件夹)
插件
下载后放到lib/ext目录下即可
导入 influxdb2.0
- 配置 influxdb
新建账号,配置 token

- 配置 jmeter
在线程组内添加一个后端控制器

- 在 influxdb UI 查看结果
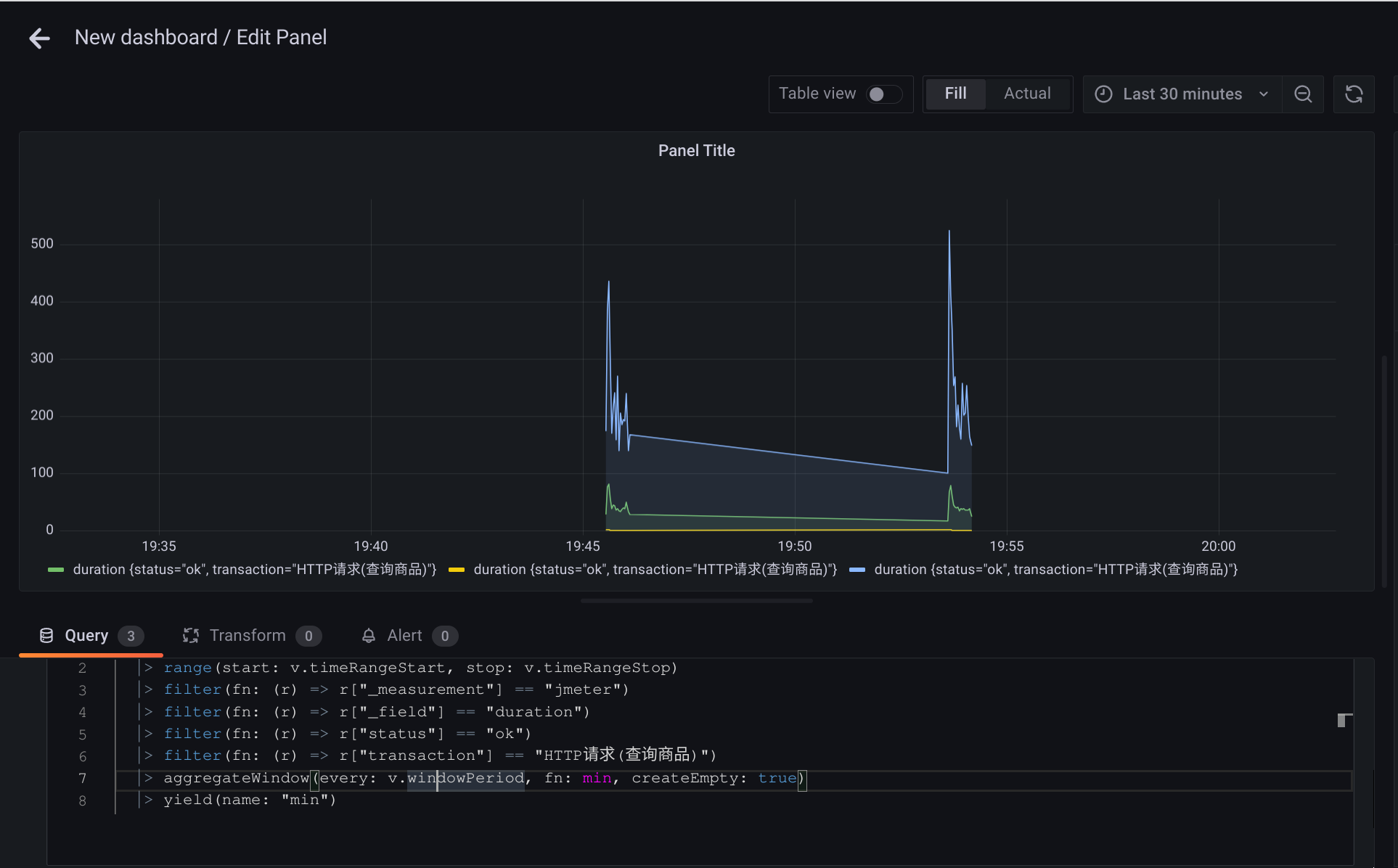
可以通过途中的可视化界面选择,也可以转换为 Flux 查询语句
gafana
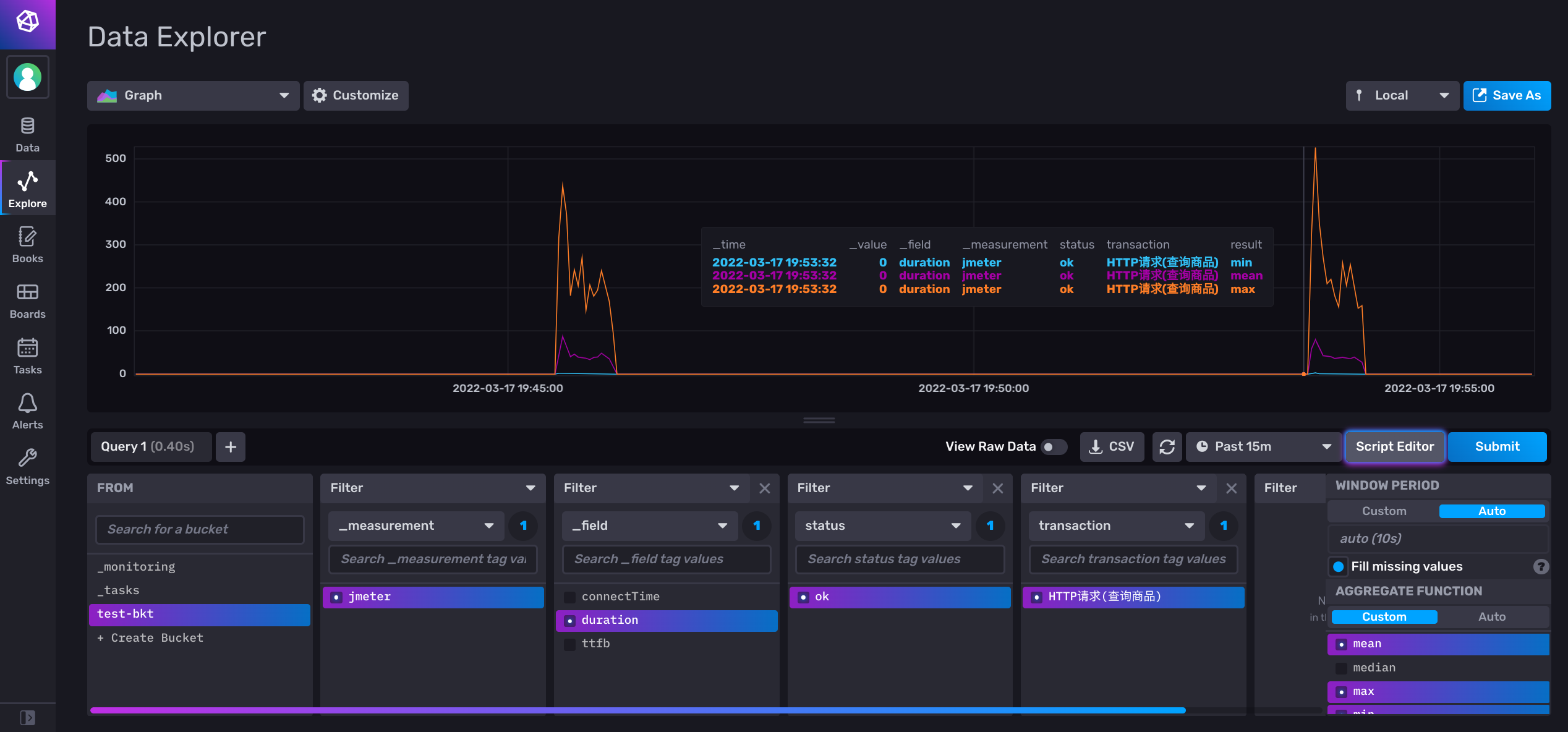
连接 prometheus
- 配置数据源
- 添加查询语句 (promQL)
- 选择合适的图标类型,定制一些图标的样式
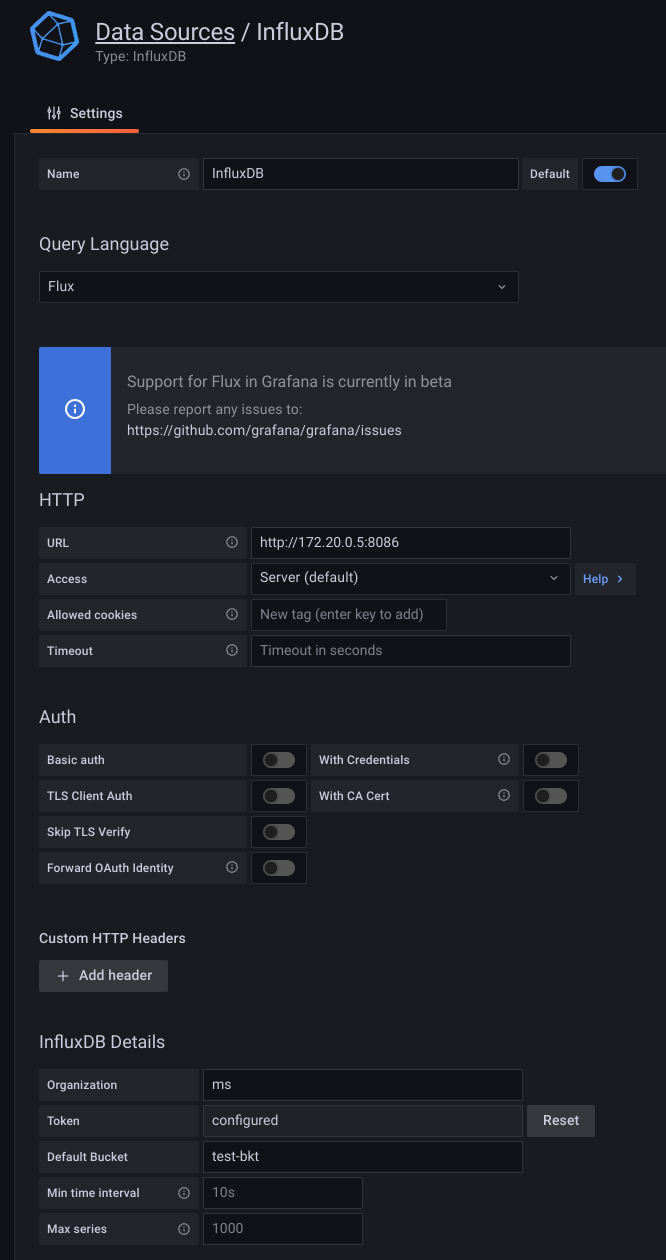
连接 influxdb
- 配置数据源 注意 url,这个 url 需要是 docker 的,不是本机的
http://172.20.0.5:8086
docker container inspect f65 | grep -i ipaddress
- 导入查询语句 (Flux)