B+ 树以及在数据库中的应用
什么是数据库
数据库,又称为数据管理系统,简而言之可视为电子化的文件柜——存储电子文件的处所,用户可以对文件中的资料运行新增、截取、更新、删除等操作 [1]。
技术初衷
在操作系统出现之后,随着计算机应用范围的扩大、需要处理的数据迅速膨胀。最初,数据与程序一样,以简单的文件作为主要存储形式。以这种方式组织的数据在逻辑上更简单,但可扩展性差,访问这种数据的程序需要了解数据的具体组织格式。当系统数据量大或者用户访问量大时,应用程序还需要解决数据的完整性、一致性以及安全性等一系列的问题。因此,必须开发出一种系统软件,它应该能够像操作系统屏蔽了硬件访问复杂性那样,屏蔽数据访问的复杂性。由此产生了数据管理系统,即数据库。
数据库管理系统
主条目:数据库管理系统
数据库管理系统(英语:Database Management System,简称DBMS)是为管理数据库而设计的电脑软件系统,一般具有存储、截取、安全保障、备份等基础功能。数据库管理系统可以依据它所支持的数据库模型来作分类,例如关系式、XML;或依据所支持的电脑类型来作分类,例如服务器聚类、移动电话;或依据所用查询语言来作分类,例如SQL、XQuery;或依据性能冲量重点来作分类,例如最大规模、最高运行速度;亦或其他的分类方式。不论使用哪种分类方式,一些 DBMS 能够跨类别,例如,同时支持多种查询语言。
数据库的分类
关系数据库
-
类似于 excel 表格,所有数据以表格的形式按行或按列存储
非关系型数据库(NoSQL)
如何实现一个数据库?
使用单文件存储的缺点
- 单个文件存储数据效率低,读取速度慢
- 如果文件过大 (几个 G), 就不能直接把整个文件读入内存再进行操作 , 即使能够读入内存,那也是完全没有必要的,我们需要的数据可能只有一行, 想要找到这一行就把所有数据全部读取是很浪费的
- 如果对文件的修改速度过快,可能会导致文件'损坏'
目标
- 加速文件读取速度
- 能够实现分快读取
- 能够在修改文件时,保证数据的完整性 (先不提)
实现思路
使用数组存储
 优点
优点
- 存储在内存中,数据量少的时候尚且可以,
- 可以通过索引 (下标) 访问数据元素,速度最快
缺点
-
当每个元素变大时,这种方式就会占用较大的内存
(依次为 学号,姓名,成绩,按照学号排序)
优化
结合之前二分的方法,我们尝试将数组中学号最小,最大,和位于中间的元素提取出来
 当我们需要查询学号为 3 的学生时,我们只需要先读取上一层的 3 个元素,在 知道 1 < 3 < 5 后就只需要在数组索引从 1 到 5 中查询学号为 3 的元素了
当我们需要查询学号为 3 的学生时,我们只需要先读取上一层的 3 个元素,在 知道 1 < 3 < 5 后就只需要在数组索引从 1 到 5 中查询学号为 3 的元素了
更大更多
 这是一种实现思路,不过不是我们讲的重点,只是为了拓展一下大家的事业
这是一种实现思路,不过不是我们讲的重点,只是为了拓展一下大家的事业
(这个东西叫跳表,可以实现对链表的二分,感兴趣的自己可以去查,我没亲手实现过)
结果
实现了查询速度的优化,但是如果每个节点都单独分一个文件,硬盘对于存储大量小文件是低效的 (这里不展开讲), 不适和在硬盘中存储
使用树存储
二叉树
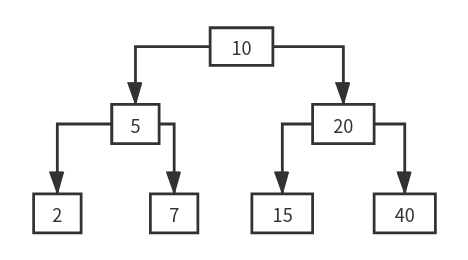 树的任意节点的左子树的节点对应的值都比右子树的值小,
二叉查找树相比于其他数据结构的优势在于查找、插入的时间复杂度较低。二叉查找树是基础性数据结构,用于构建更为抽象的数据结构,如集合、多重集、关联数组等。
树的任意节点的左子树的节点对应的值都比右子树的值小,
二叉查找树相比于其他数据结构的优势在于查找、插入的时间复杂度较低。二叉查找树是基础性数据结构,用于构建更为抽象的数据结构,如集合、多重集、关联数组等。
我们分析一下对于使用二叉树进行查询需要的次数
# 1. '**'在 python 中表示次方,print(3**2)
# 2. 数字中间的下划线会被忽视,作用只是为了看数字时更方便
2**27 = 134_000_000
2**26 = 67_000_000
2**25 = 34_000_000
2**24 = 17_000_000
从 1 亿数据中查询最大只需要 27 次,效果非常好,但是这还远远不够
让我们继续分析
查询的耗时在哪里
对于二叉树
从磁盘中读取一个节点
|
得到节点内存储的学号
|
比较该节点的学号和我们需要查询的学号
|
找到左子树或右子树在硬盘中的位置
|
进行下一次
我们这里先讨论机械硬盘的条件下
下面就是一张机械硬盘的图片,最重要的就是磁头和磁盘两个结构,每次硬盘把文件读取到内存中,都需要先把磁头旋转到对应的位置,才能开始读取存储在文件中的数据

因为从硬盘读取数据的速度远远低于比较节点的速度,所以我们可以尽量降低二叉树的深度 (即降低检索数据的次数),
多叉树
B 树

假如我们一个节点可以存储更多分支,我们就能用更少的次数查到相应的数据节点,这本身是一种很好的结构,已经能够解决一些问题, PostgreSql 就提供了 B 树作为存储结构
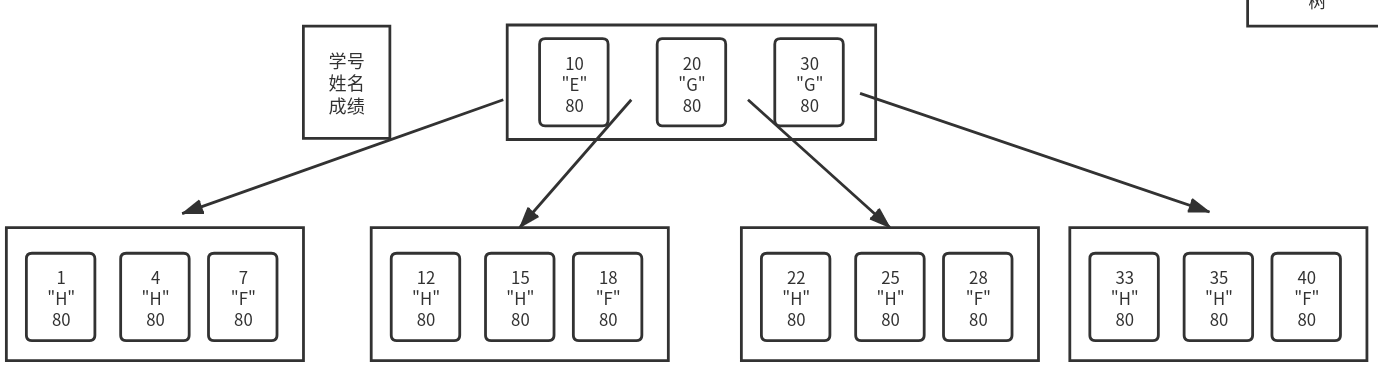 现在每个节点存储了多个元素数据,每个元素中都包含了一个学生的信息,
现在每个节点存储了多个元素数据,每个元素中都包含了一个学生的信息,
每次查询时,如果学号匹配我们就直接返回结果,如果不匹配,就继续深入下一层
缺点
但是在真实环境下,一个节点不可能只有一个序号,我们现在把图扩充下
存储的信息越多,单个元素就越大,我们能读取到内存中的元素个数就会变少,树的分叉就不会太多为了让分叉足够多,我们引入 B+ 树
B+ 树
为了能够让一个节点存储更多的元素,我们决定抛弃节点中存储的无用的信息,之保留学号这一项数据,然后之在叶子节点 (就是最后一层的节点) 存储完整的节点
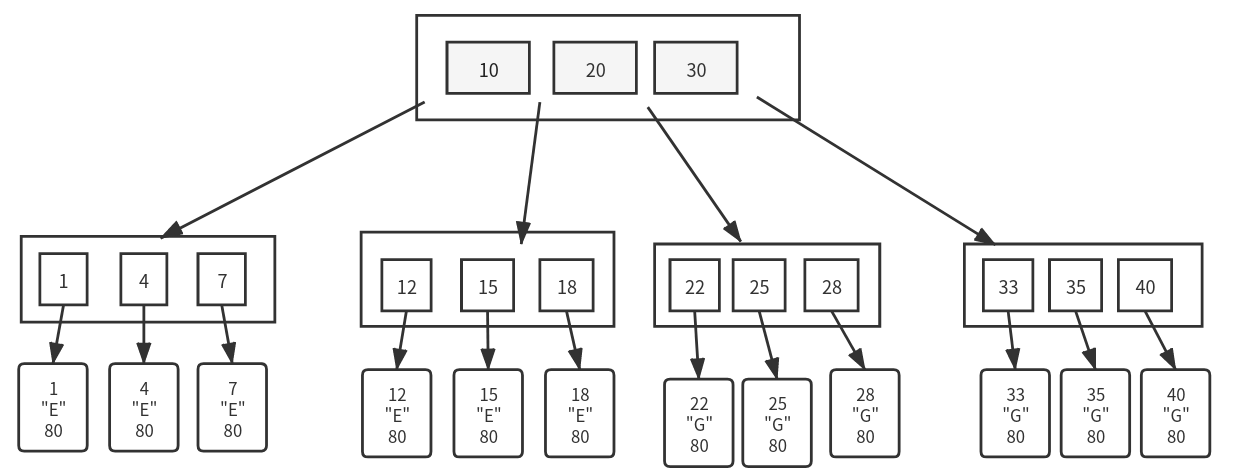
现在我们得到最好的结构了,我们可以一次加载一个节点,每个节点可能有几百几千个学号,假如有 100 个分支,两层数据就能够存储 100 * 100 = 10_000 个数据,在 10000 个人中只用两次就能查到我们需要的数据,想对于二叉树 2**13 = 8192 需要大概 13 次,我们现在磁盘只需要旋转 2 + 1 次就能读到数据,这是一个飞跃。
小问题
学号为 10, 20, 30 的学生的数据去哪了?没了?
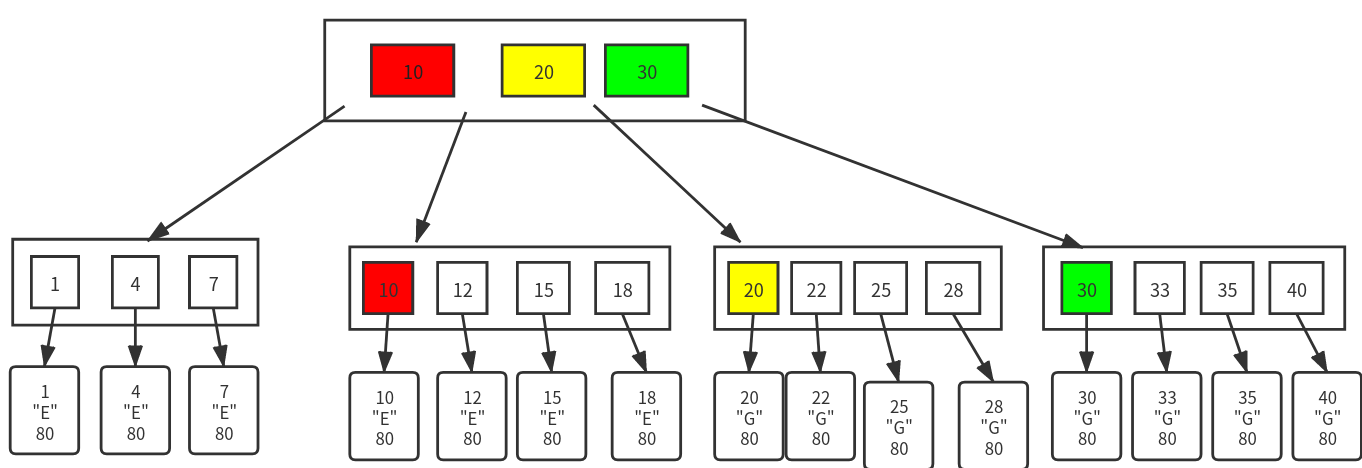
比如我们现在需要查询学号为 10 的学生的数据,我们在在查询第一层时已经找到了 10,但是依然不能停,需要继续想下查找,知道找到最后一层节点为止
小拓展
把最后一层的数据串起来,我们就能实现区间查询,比如查询学好为 12 到 22 的所有学生的数据
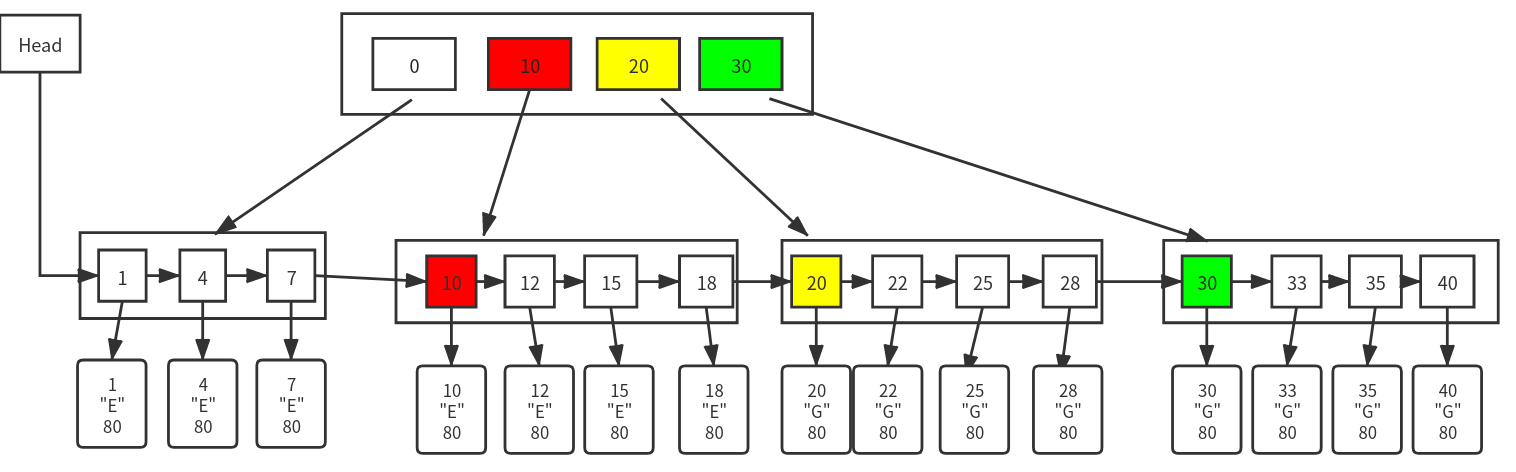
一个 demo

快要忘记的固态硬盘
如果你用的是固态硬盘,那么 B+ 树......卒