大数据
使用 VM 搭建 hadoop 集群
1. 准备
- centos7.5 镜像
- JDK8
- Hadoop
- 参考链接
2. 安装 hadoop101 虚拟机
- 软件选择:最小安装是纯命令行
- 安装位置:选择手动和以自由配置盘符配置及大小,设备类型 (LVM 相比于标准分区能自由扩缩容)
- KDUMP 可以暂时不要
- 设置用户名密码:示例 username: hadoop101 password: 000000
3. 配置本机网络环境
- 关闭防火墙
- VM 配置 VMnet8 编辑 -> 虚拟网络编辑器
- Windows 配置 VMnet8
4. 配置虚拟机网络环境
- 关闭虚拟机防火墙:
systemctl disable firewalld.service - 关闭 NetworkManage:
systemctl stop NetworkManagersystemctl disable NetworkManager
- !!! 修改网卡配置:
vim /etc/sysconfig/network-scripts/ifcfg-ens33
BOOTPROTO=static #启用静态 IP 地址 ,默认为 dhcp
IPADDR=192.168.182.3 #设置 IP 地址 (这台虚拟机想要的 ip)
NETMASK=255.255.225.0 #设置子网掩码
GATEWAY=192.168.182.2 #设置网关 (和外部的网关相同)
- 重启网卡:
service network restart可以通过ping 8.8.8.8检测是否通
5. 克隆前
- 安装辅助包管理器:
yum install -y epel-release - 未知:
kill -9 3030 - 卸载系统自带 JDK:
- 查看:
rpm -qa | grep java - 卸载:
sudo yum remove packagename
- 修改虚拟机 host
- 修改 hostname 如下:
nano /etc/hostname
hadoop101
- 修改 hosts 如下:
nano /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.93.21 hadoop101
192.168.93.22 hadoop102
192.168.93.23 hadoop103
6. 克隆 (完整克隆) 后
- 通过 vmware 进行 clone 出 n 台相同的虚拟机
- 修改每台克隆出的网卡 IPADDR:
vim /etc/sysconfig/network-scripts/ifcfg-ens33 - 修改 hostname:
nano /etc/hostname
7. 安装及配置环境变量
- 安装软件 为了方便统一管理
- 压缩包目录:
/opt/software - 解压目录:
/opt/module解压: - 给权限:
chmod 777 /opt/software - 解压 (-C 指定解压目录):
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
- 修改环境变量 为了永久修改环境变量:修改文件
sudo nano /etc/profile.d/users.sh如下
#JAVA
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
- 重置
source /etc/profile::: warning 使用export PATH=$PATH:xxxxx会在终端关闭后失效 :::
8. 配置集群分发脚本和免密登录
- scp 服务器间拷贝
# 将当前服务器的/opt/module/jdk1.8.0_212 目录拷贝到 hadoop102 服务器的/opt/module 目录下
# 值得注意的是,hadoop102 服务器下的/opt/module 目录必须存在
# -r 指递归复制整个目录
# root 是指 hadoop102 的用户
scp -r /opt/module/jdk1.8.0_212 root@hadoop102:/opt/module
- rsync 远程同步工具
# 值得注意的是,每个服务器都需要安装
yum -y install rsync
# -a 表示归档拷贝
# -v 表示显示拷贝过程
rsync -av /opt/module/hadoop-3.1.3/ root@hadoop102:/opt/module/hadoop-3.1.3/
# 让两个文件夹同步
- 分发脚本 (起名:xsync)
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop101 hadoop102 hadoop103
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
::: danger
空格必须加:
if [ -e $file ]等号两边的空格必不能加:pdir=$(cd -P $(dirname $file); pwd)$@返回所有命令行参数,所以可以一次同步多个文件 (夹)
:::
- 后续处理 文件创建在/bin/下:
/bin/xsync方便直接调用
# 给运行权限
chmod +x xsync
# 测试同步环境变量
xsync /etc/profile.d/
- 免密登录
cd /root/.ssh
# 生成私钥公钥
ssh-keygen -t rsa
# 分发密钥
ssh-copy-id hadoop101
ssh-copy-id hadoop102
ssh-copy-id hadoop103
9
HDFS
日志型,只允许追加
HBase
基于 HDFS,不会将旧数据删除
数据模型
HBase 是一个稀疏的 (不同时间没有数据),多维度 (4 个维度在能限定到一个单元格) 的,排序的映射表
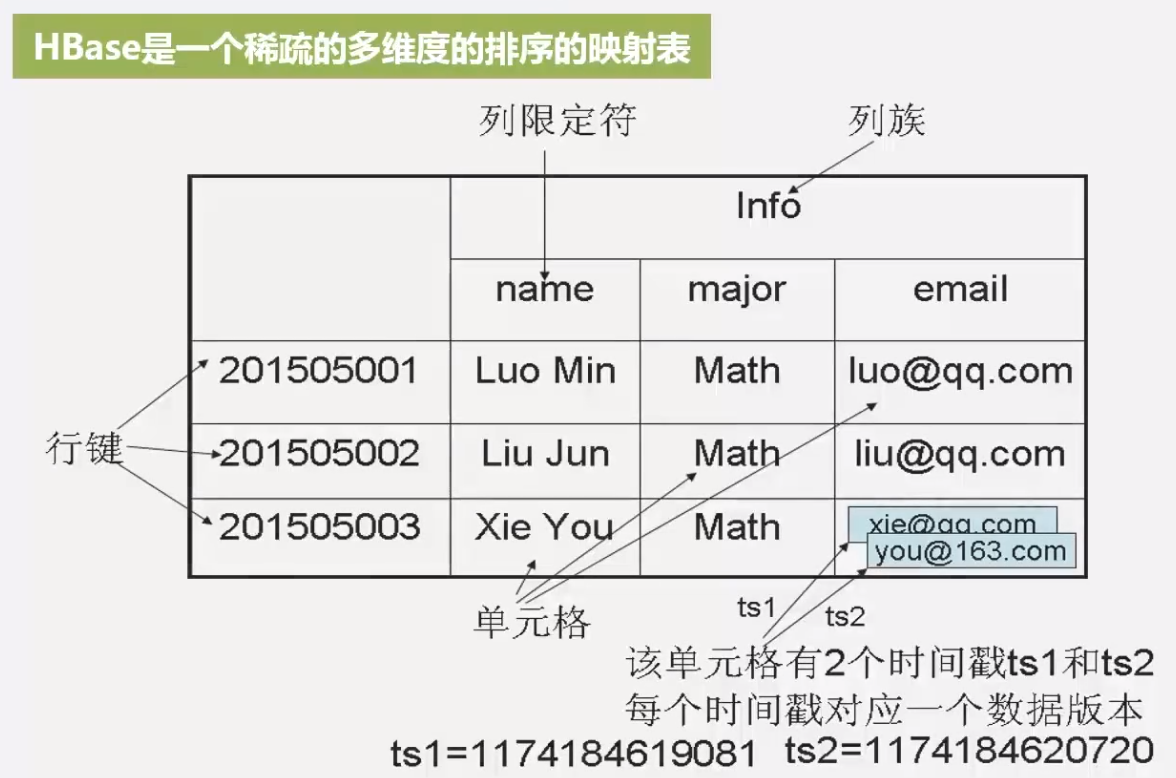
概念视图
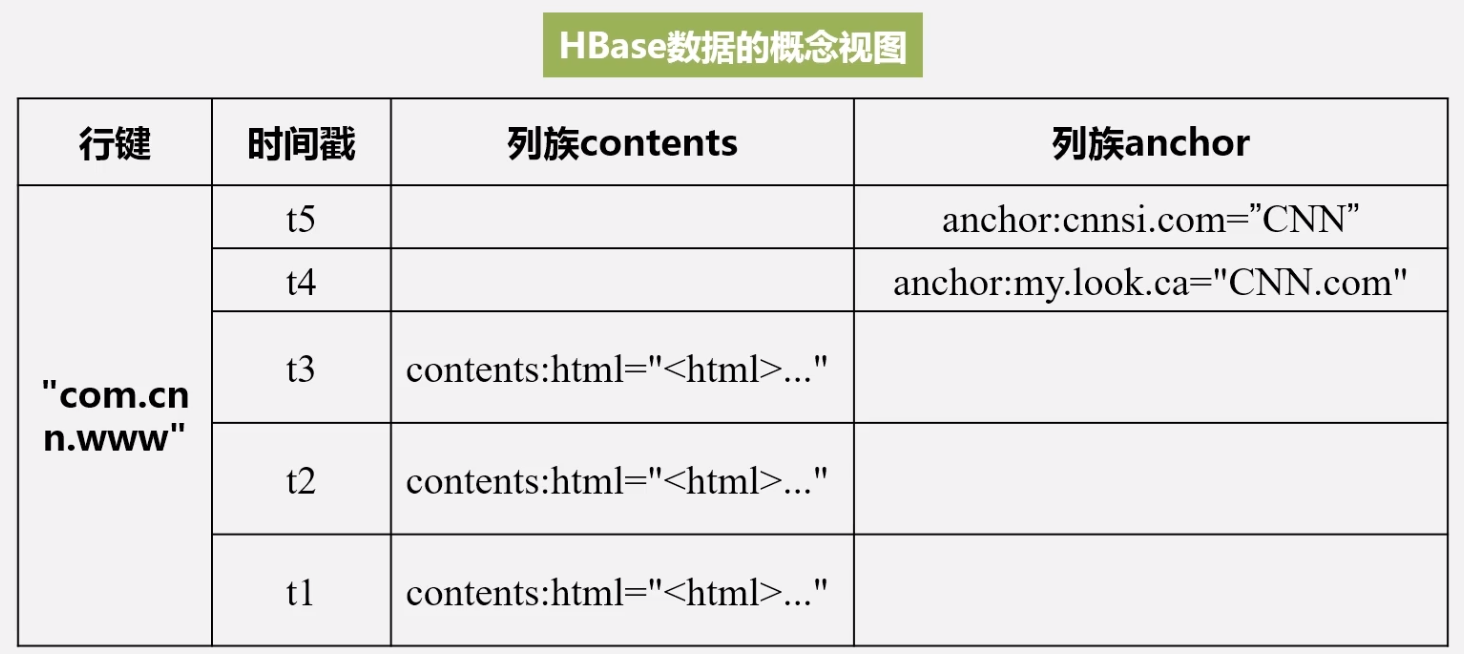 不同时间可能没有数据,体现了 HBase 是稀疏表
不同时间可能没有数据,体现了 HBase 是稀疏表
物理视图
列标识并没有区分
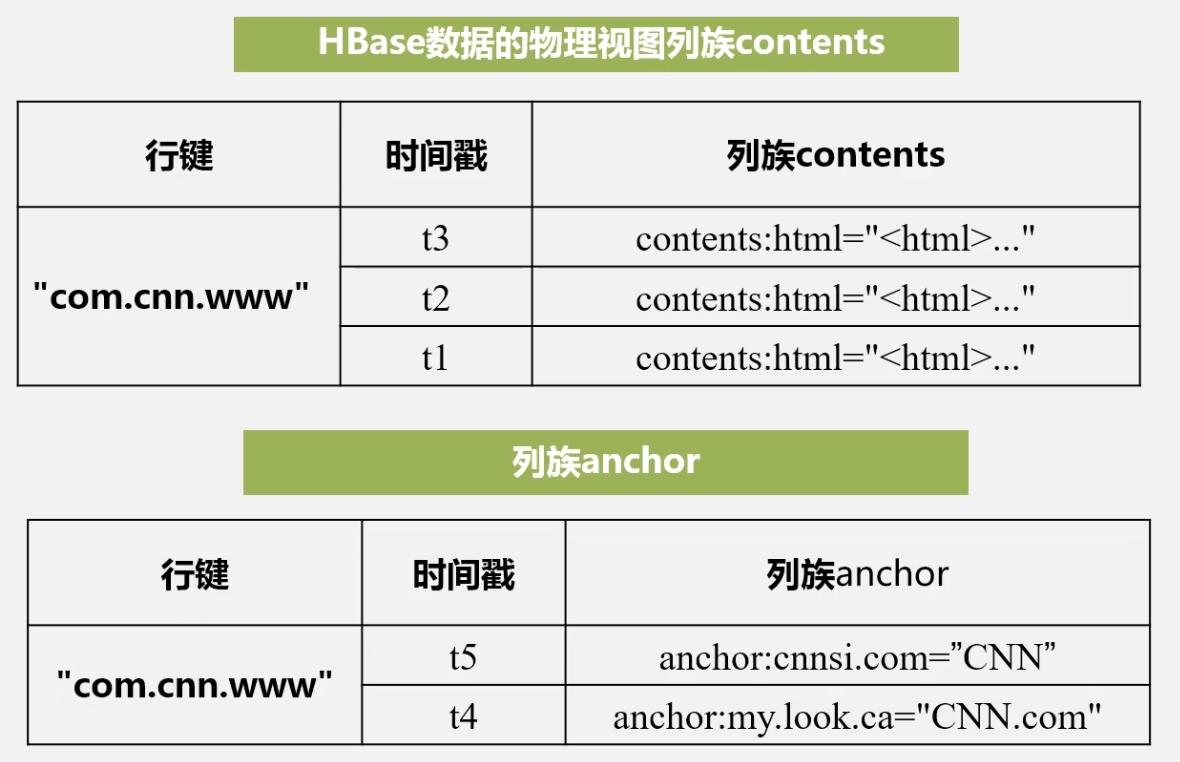
按行按列的区分
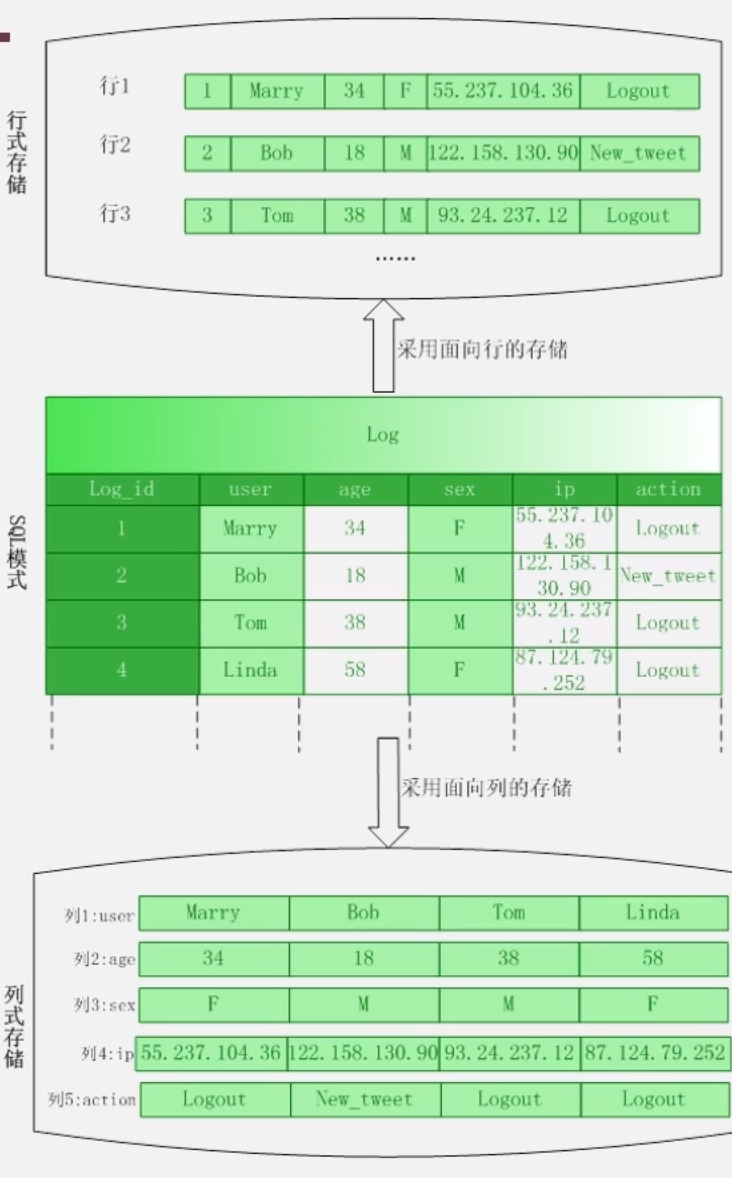
按行:
- 不便于读取某一列数据,必须扫描所有行,并把每行的某个字段取出来
按列:
- 压缩性能好,按列存,数据类型相同,能够更好的压缩
实现原理
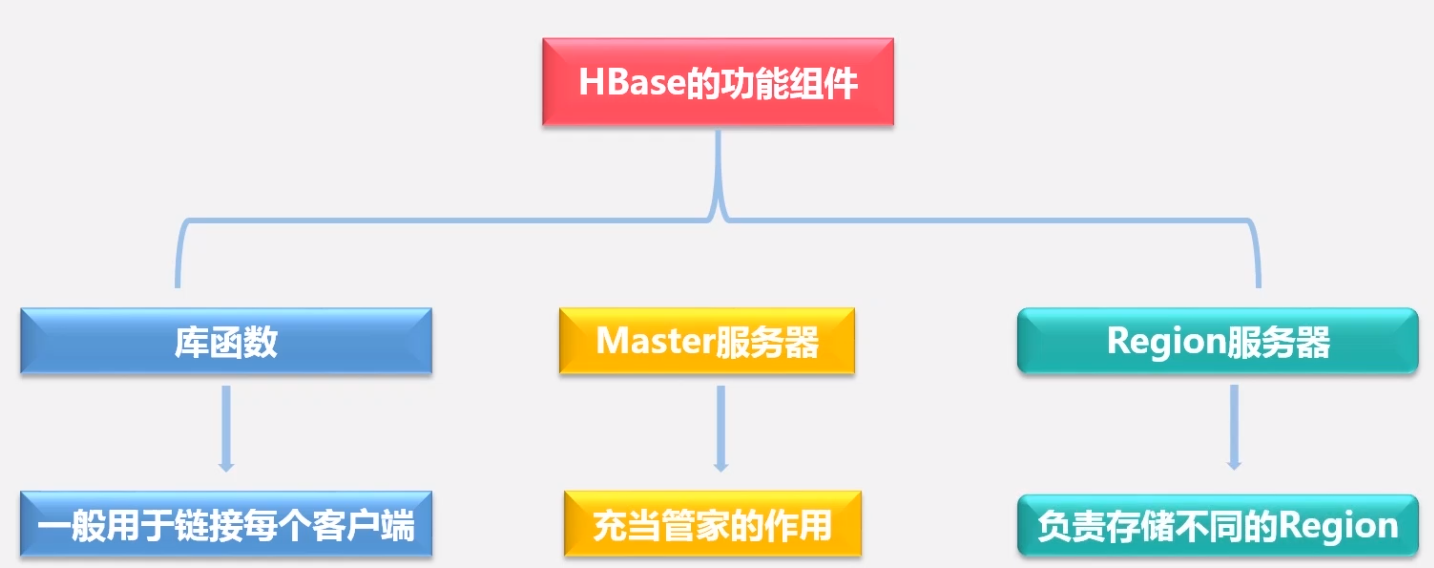
服务器划分
- master 服务器负责管理写请求,负载均衡等
- 客户端并不依赖 master 服务去找到数据位置
- 用户直接访问的是 region 服务器
物理存储
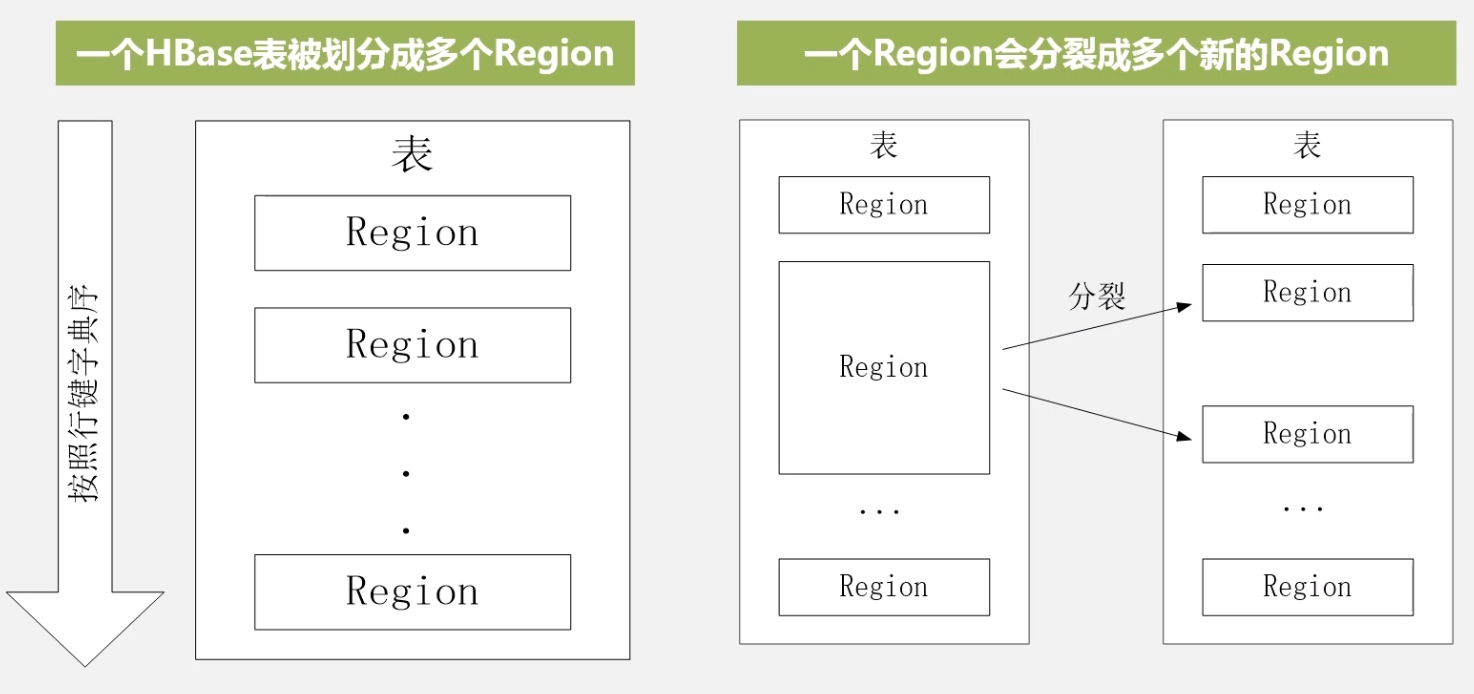
- 不同的 region 不许存储在同一个服务器上,一个服务器可以存储多个 region(1-2G, 10-1000 个)
- region 太大了就会垂直分裂 (操作指针,速度较快),分裂时用户读取的依然是之前的
region,当服务器经过合并,写入新的文件之后,新来的用户彩绘访问新的 region
索引结构
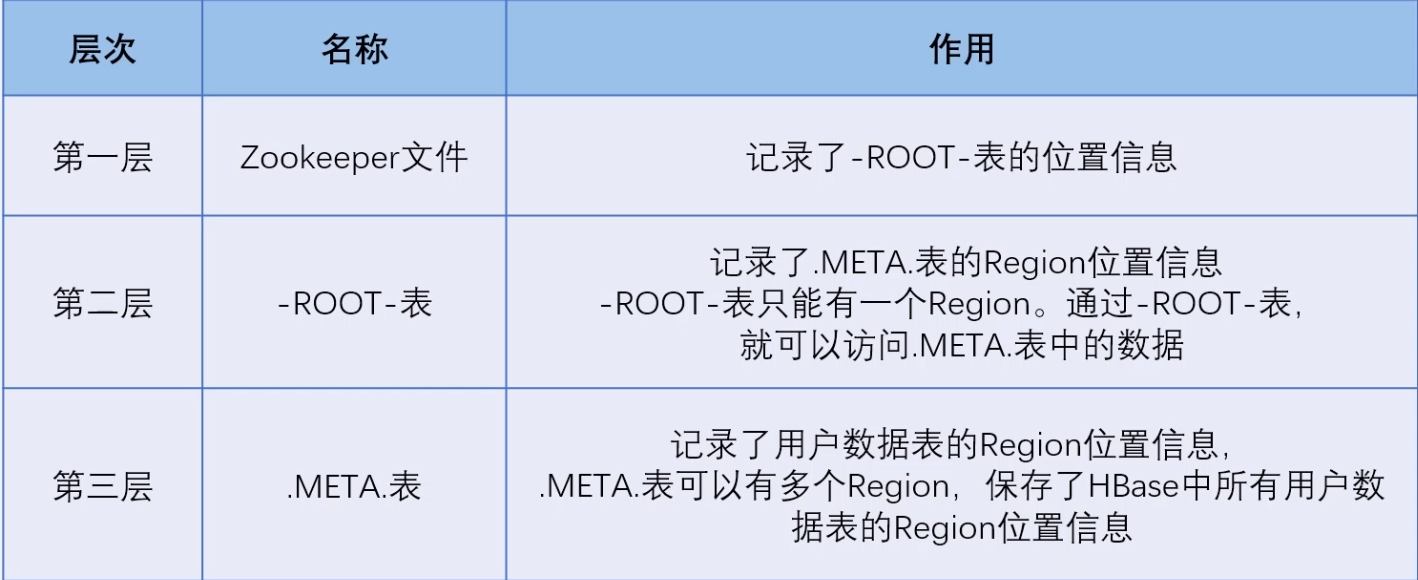
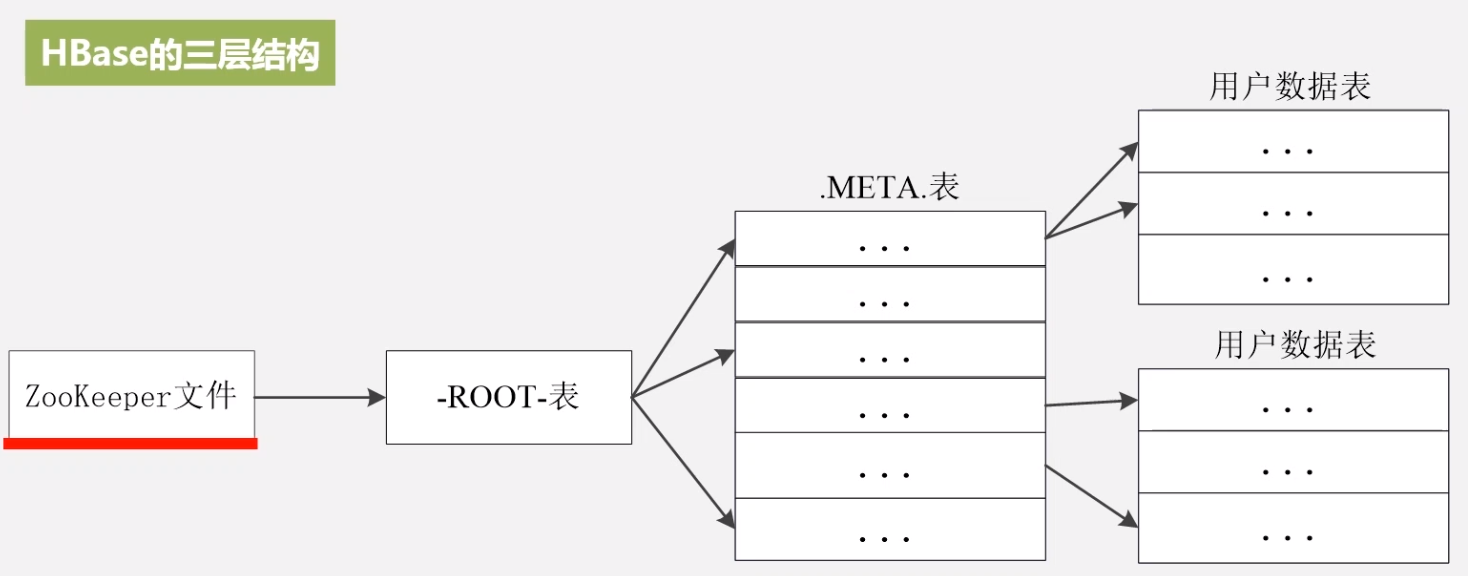 各个层次的作用
各个层次的作用
 3 层结构完全足够使用,对于经常访问的可以增加缓存
3 层结构完全足够使用,对于经常访问的可以增加缓存
- 如何解决缓存失效,缓存失效的话数据就找不到了
运行架构
架构图
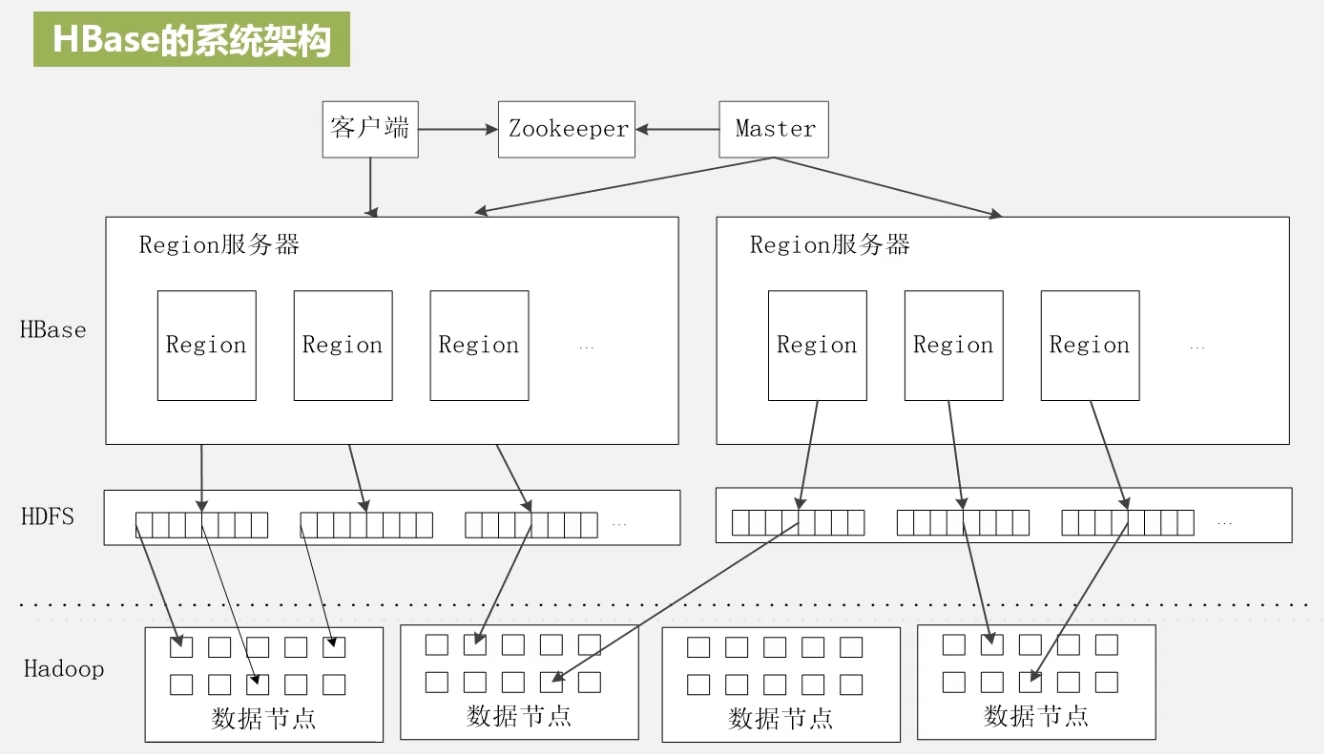 master:
master:
- 对数据表进行增删改查
- 负载均衡,把负载大的服务器上的 region 表拿到其他负载小的服务器上
- 管理 region 的分裂合并操作之后的发布
- 重新分配故障服务器上的 region
region 写入 HDFS
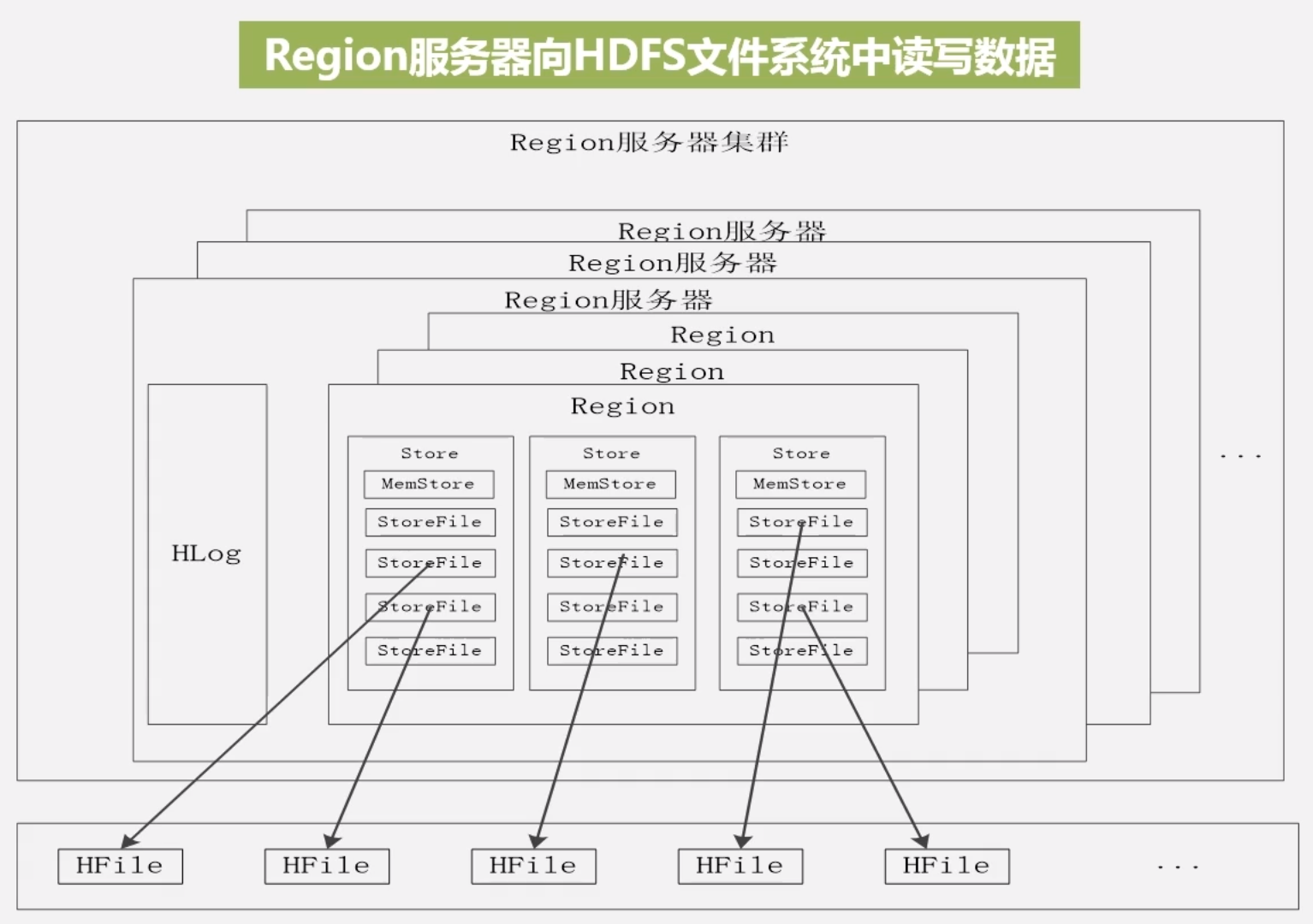 对于单个 region 服务器,上面存储了多个 region 块,每个列族被划分为一个 store
对于单个 region 服务器,上面存储了多个 region 块,每个列族被划分为一个 store
锁与 resion 块共用一个 Hlog 文件
region 将数据写入 HDFS 会线写入 memStore 中 (缓存),缓存满了之后,刷入 StoreFile 中,StoreFile 就是 HFile, HDFS 中的数据格式
用户写入 Region
用户写入请求被分配给 region
- 写入缓存
- 写入日志 (Hlog), 必须写入磁盘才算成功
- 系统将缓存周期性刷入磁盘,并在 Hlog 写入标记
- 每次刷写都会生成一个 StoreFile
- 多个 StoreFile 会合并为大文件,太大就会引发 StoreFile 的分裂,region 就分裂了
zookeeper 监听 Region 服务器,如果 Region 服务器发生故障,就会通知 Master 服务武器,Master 服务器将 Region 服务器上的 Hlog 文件拉取过来,并根据日志文件将所有 Region 分配到其他可用的 Region 服务器
优化存储
-
时间靠近的数据存在一起:
用
Long.Max_VALUE - timestamp作为行键,最新的数据能够快速命中 -
提升读写性能
设置
HColumnDescriptor.setlnMemory = true, 将 Region 服务器的 Region 放入缓存中 -
删除旧版本数据 设置
HColumnDescriptr.setMaxVersionsMaxVersions = true,只会保留最新版本 -
过期自动清除 设置
setTimeToLive(2 * 24 * 60 * 60)超过两天就自动清除
二级索引
Hindex: 依赖触发器在插入数据后同时插入索引表 HBase + Redis: 将索引暂时存入 redis,之后在刷入 HBase Solr + HBase: 高性能全文索引,由 Solr 构建索引得到数据的 RowKey
NoSQL

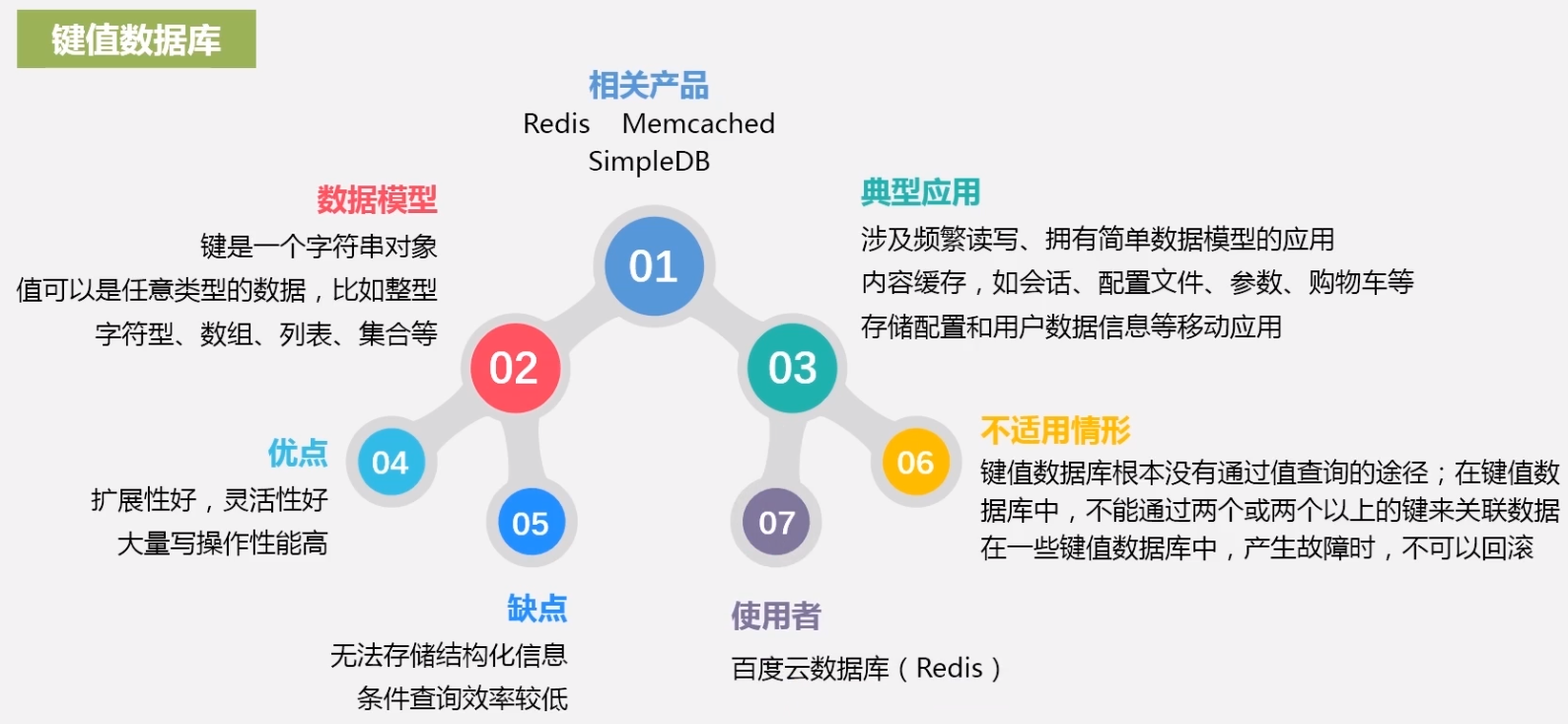
键值数据库
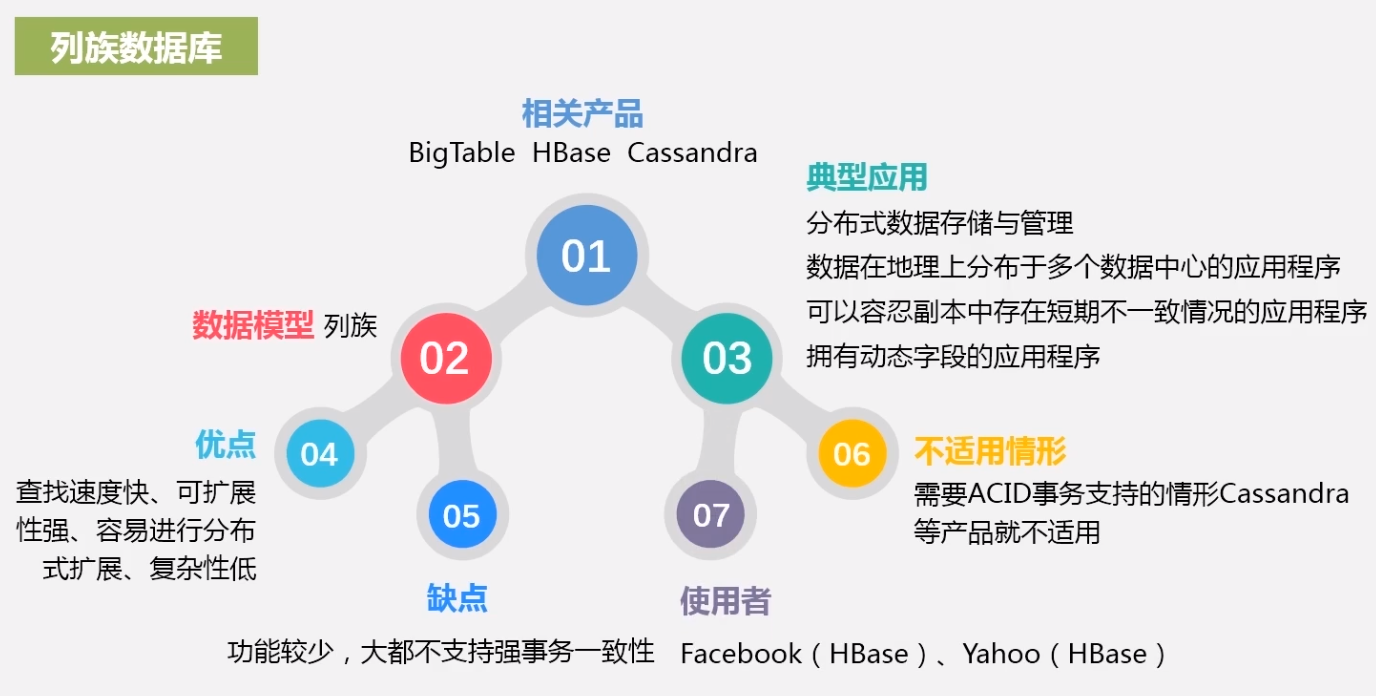
列族数据库
文档数据库

MapReduce
分布式并行编程模型,相比与传统的并行编程框架的区别
模型简介
|
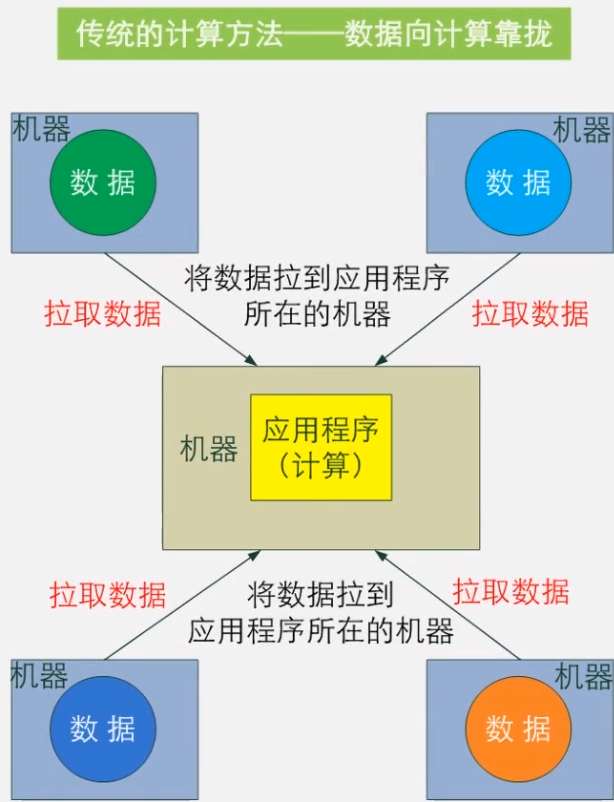
传统的计算方法是数据向计算靠拢
|
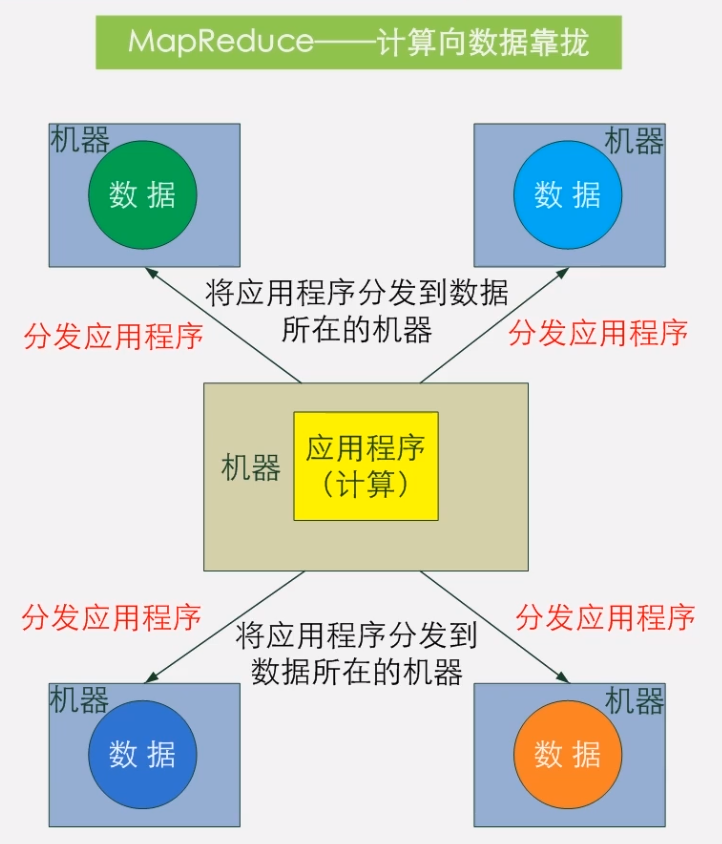
MapReduce 计算项数据靠拢
|
体系结构
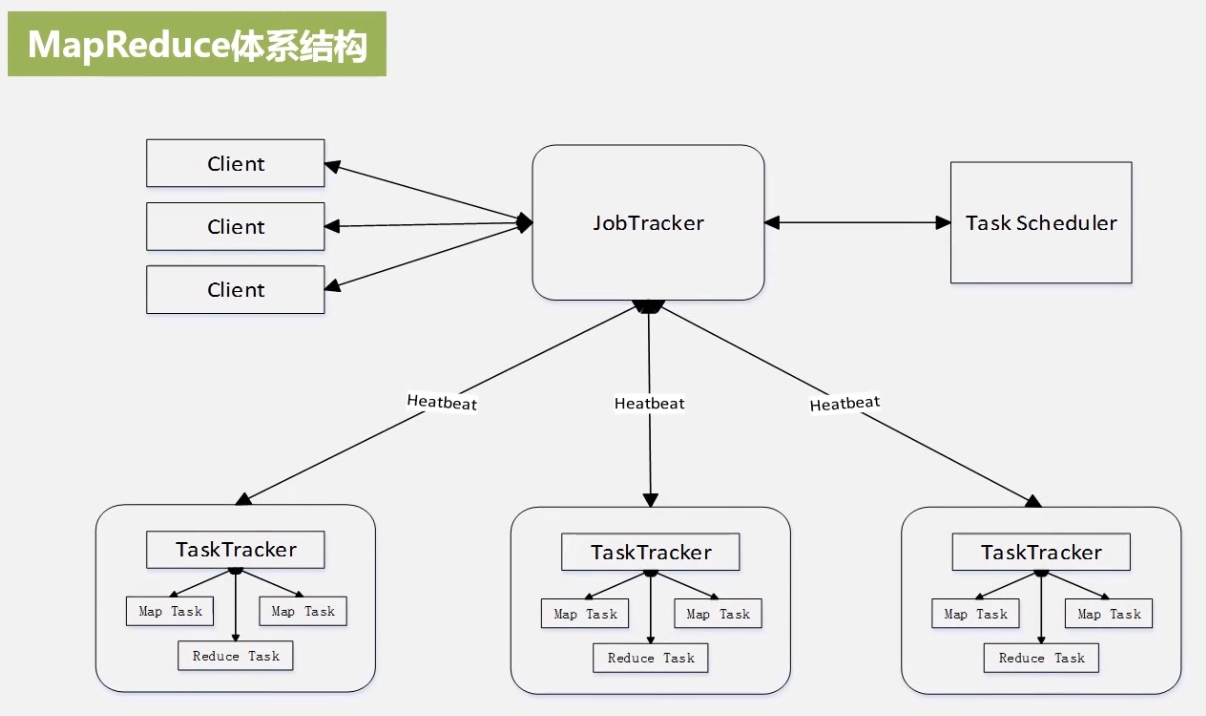
Client
- 用户将编写的程序提交到 Client
- 通过 Client 提供的借口查看作业的运行状态
JobTracker
- 负责资源监控
- 负责作业调度 (依靠 TaskSchedular 决定任务应该分发给那个 Taskracker)
- 监测底层其他 Taskracker 以及当前运行的 Job 的状况
- 如果检测到失败,需要把 Job 转移到其他节点,并继续追踪
TaskTracker
- 执行具体的相关任务,一般是 JobTracker 发来的命令
- 把自己的资源使用情况,任务运行进度通过心跳的方式发送给 JobTracker