查询引擎:推送与拉取
考虑以下的 SQL 语句
SELECT DISTINCT customer_first_name
FROM customer
WHERE customer_balance > 0
查询优化器通常将这样的 SQL 查询编译成一系列离散运算符:
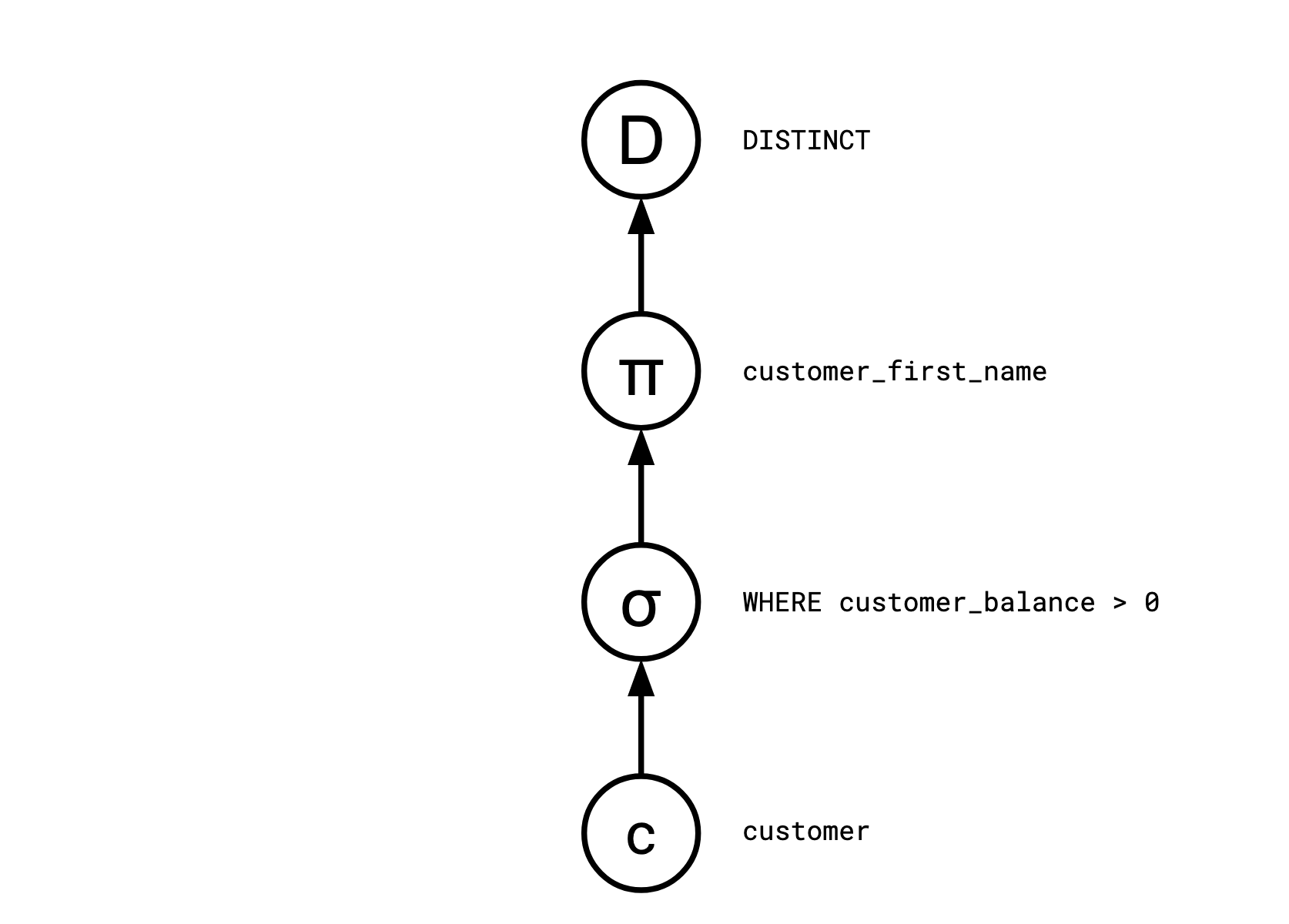
Distinct
<- Map(customer_first_name)
<- Select(customer_balance > 0)
<- customer
在基于 Pull 的系统中,消费者 customers 驱动系统。每个运算符运算后都会产生一个新行:用户将向根节点(Distinct)请求一行,这一行回向
Map 询问一行,接着向 Select 询问一行,依此类推。
在基于 Push 的系统中,生产者 producers 驱动系统。每个运算符,当他接收到数据时,就会告知下游的运算符,customer
作为查询基表回告诉 Select 自己的信息,接着是 Map、Distinct。
Pull-Based 查询引擎
基于拉取的查询引擎一般也被称为使用 Volcano 或 Iterator 模型。这是最古老和最著名的查询执行模型,并以 1994 年标准化其约定的论文命名。
首先我们有一个关系,我们通过 Scan 把它专为一个迭代器
let customer = [
{ id: 1, firstName: "justin", balance: 10 },
{ id: 2, firstName: "sissel", balance: 0 },
{ id: 3, firstName: "justin", balance: -3 },
{ id: 4, firstName: "smudge", balance: 2 },
{ id: 5, firstName: "smudge", balance: 0 },
];
function* Scan(coll) {
for (let x of coll) {
yield x;
}
}
接下来为他实现一些操作符
function* Select(p, iter) {
for (let x of iter) {
if (p(x)) {
yield x;
}
}
}
function* Map(f, iter) {
for (let x of iter) {
yield f(x);
}
}
function* Distinct(iter) {
let seen = new Set();
for (let x of iter) {
if (!seen.has(x)) {
yield x;
seen.add(x);
}
}
}
翻译我们的查询语句
SELECT DISTINCT customer_first_name FROM customer WHERE customer_balance > 0
Distinct(
Map(
(c) => c.firstName,
Select((c) => c.balance > 0, Scan(customer))
)
),
Push-Based 查询引擎
基于推送的查询引擎,有时也称为 Reactive、Observer、Stream 或回调地狱模型,如您所料,与我们之前的示例类似,但它颠覆了它。让我们从定义 Scan 开始
let customer = [
{ id: 1, firstName: "justin", balance: 10 },
{ id: 2, firstName: "sissel", balance: 0 },
{ id: 3, firstName: "justin", balance: -3 },
{ id: 4, firstName: "smudge", balance: 2 },
{ id: 5, firstName: "smudge", balance: 0 },
];
function Scan(relation, out) {
for (r of relation) {
out(r);
}
}
我们将“此运算符告诉下游运算符”构建为它需要调用的闭包。
剩下的运算符也是如此
function Select(p, out) {
return (x) => {
if (p(x)) out(x);
};
}
function Map(f, out) {
return (x) => {
out(f(x));
};
}
function Distinct(out) {
let seen = new Set();
return (x) => {
if (!seen.has(x)) {
seen.add(x);
out(x);
}
};
}
查询语句建模:
let result = [];
Scan(
customer,
Select(
(c) => c.balance > 0,
Map(
(c) => c.firstName,
Distinct((r) => result.push(r)),
),
),
);
区别
在基于 Pull 的系统中,所有的操作符都是惰性的,只有当数据需要时,操作符才会开始计算(yield)。这也意味着系统的行为和用户的行为紧密耦合。
再基于 Push 的系统中,系统开始处于空闲状态,直到他接受到一行数据。因此系统的工作和消费者是解耦的。
基于 Push 的系统还需要创建一个缓冲区,并将查询结果放到里面。这就是基于 Push 的系统给人的感觉。它会假设消费者不存在,当被请求时,能够立即作出响应。
DAG, yo
SQL 中有一个 With 结构,它允许在查询中多次引用同一个结果集:
WITH foo as (<some complex query>)
SELECT * FROM
(SELECT * FROM foo WHERE c) AS foo1
JOIN
foo AS foo2
ON foo1.a = foo2.b
基于 Push 的系统能够优化查询结构,复用结果集,而基于 Pull 的系统无法做到这一点。