Go 语言
###./ 基础
格式化
fmt.Printf("type %T value %v \n", a, a)
循环
if num := 10; num > 0 {
fmt.Println(num)
}
for i := 1; i < 10; i++ {
fmt.Println(i)
if i == 3 {
break
}
}
finger := 2
switch finger {
case 1:
fmt.Println(1)
case 2:
fmt.Println(2)
fallthrough
default:
println("sss")
}
dd := 1
switch {
case dd > 0:
println(0)
case dd > -1:
println(-1)
}
数组
数组有固定大小,数组的大小是类型的一部分,因此 [5]int 和 [25]int 是不同类型
a := []int{2}
a[0] = 1
fmt.Println(a)
var b [3][2]int
b = [3][2]int{
{1, 2},
{1, 2},
{1, 2},
}
fmt.Println(b)
veggies := []string{"potatoes", "tomatoes", "brinjal"}
fruits := []string{"oranges", "apples"}
food := append(veggies, fruits...)
fmt.Println("food:", veggies, fruits, food)
fmt.Println("food:", cap(veggies), cap(fruits), cap(food))
fmt.Println("food:", len(veggies), len(fruits), len(food))
nums := []int{1, 2}
change(nums...)
pln(nums...)
map
// map 的零值为 nil,必须使用 make 初始化
// map 是 引用类型,当 map 被赋值给另一个变量是后,他们共享一个
// map 不能使用==判断,==只能用来判断 map 是否为 nil,应该遍历字典元素去比较两个字典
var mm map[string]int
// mm["s"] = 1 // 回报错,map is nil
// fmt.Printf("%T %v \n", mm, mm) // 这里虽然能打印出 map[],但是无济于事
if mm == nil {
mm = make(map[string]int)
mm["s"] = 1
fmt.Printf("%T %v \n", mm, mm)
}
mmm := map[string]int{
"aaa": 1,
}
if v, ok := mmm["aa"]; ok == true {
fmt.Println(v)
delete(mmm, "aa")
} else {
fmt.Println("no such key")
fmt.Println(len(mmm))
for k, v := range mmm {
fmt.Println(k, v)
}
}
字符串 与 切片
// 字符串
name := "Señor"
for i := 0; i < len(name); i++ {
fmt.Printf("%c", name[i])
}
fmt.Printf("\n")
for _, v := range name {
fmt.Printf("%c", v)
}
fmt.Printf("\n")
name_ := []rune(name)
for i := 0; i < len(name_); i++ {
fmt.Printf("%c", name_[i])
}
当对切片调用append(slice, ...elems)是,如果超出切片的 cap,就会重新分配内存空间,因此必须需要用变量接受返回值
//关于切片
// a[x] 是 (*a)[x] 的简写形式
// arr := [3]int{1, 2, 3}
// modify(&arr)
// modify(arr[:]) 这种更常用
// arr++ 这种直接进行指针操作不被允许
func modify1(arr *[3]int) {
(*arr)[0] = 90
}
func modify2(arr *[3]int) {
arr[0] = 90
}
func change(elems ...int) {
for i, v := range elems {
v += 1 // 无效
elems[i] += 1 // 有效
}
}
func pln(elems ...int) {
for i, v := range elems {
fmt.Printf("index: %v value %v\n", i, v)
}
}
结构体
- 结构体是值类型。如果它的每一个字段都是可比较的,则该结构体也是可比较的。如果两个结构体变量的对应字段相等,则这两个变量也是相等的。
- 如果结构体包含不可比较的字段,则结构体变量也不可比较。
书写
-
匿名结构体:string,int 就是字段名,字段不能重复
type Person struct { string int } person := Person{"aa", 1} fmt.Println(person.int, person.string) -
提升字段:嵌入的结构体,可以直接调用里面的字段
type Group struct { string int Person } -
匿名 + 提升,向上面的情况
匿名的类型可以重复,但是会以自身的为准
group := Group{"bb", 1, person} fmt.Print(group.string, group.string)
结构体 Tag
格式 空格分割的键值对
使用 示例:json 库能够反序列化结构体
- 如果加上 omitepty,当结构体为空是就会被忽略
- 如果不加,为空的字段会被解析为空字符串""
type Person struct {
Name string `json:"name"`
Age int `json:"age"`
Addr string `json:"addr"` // ,omitempty
}
func main() {
p1 := Person{
Name: "Jack",
Age: 22,
}
data1, _ := json.Marshal(p1)
fmt.Printf("%s\n", data1)
}
可以通过反射读取 tag
// 三种获取 field
field := reflect.TypeOf(obj).FieldByName("Name")
field := reflect.ValueOf(obj).Type().Field(i) // i 表示第几个字段
field := reflect.ValueOf(&obj).Elem().Type().Field(i) // i 表示第几个字段
// 获取 Tag
tag := field.Tag
// 获取键值对
labelValue := tag.Get("label") // 获取不到就会返回 ""
labelValue,ok := tag.Lookup("label")
- 获取键值对,有 Get 和 Lookup 两种方法,但其实 Get 只是对 Lookup 函数的简单封装而已,当没有获取到对应 tag
的内容,会返回空字符串。
func (tag StructTag) Get(key string) string { v, _ := tag.Lookup(key) return v } - 空 Tag 和不设置 Tag 效果是一样的
方法 & 函数
结构体上的方法
- 结构体方法:不管是一个值,还是一个可以解引用的指针,调用这样的方法都是合法的。或者说:用一个指针或者一个可取得地址的值来调用都是合法的
- 匿名字段的方法:属于结构体的匿名字段的方法可以被直接调用,就好像这些方法是属于定义了匿名字段的结构体一样。
type rectangle struct {
length int
width int
}
func (r *rectangle) area() {
r.length += 1
}
// func (r rectangle) area() {
// r.length += 1
// }
r := rectangle{
length: 10,
width: 5,
}
r.area()
(&r).area()
// {12, 5}
// 如果改为 不带*的方法,{10, 5}
那么什么时候使用指针接收器,什么时候使用值接收器?
- 一般来说,指针接收器可以使用在:对方法内部的接收器所做的改变应该对调用者可见时。
- 指针接收器也可以被使用在如下场景:当拷贝一个结构体的代价过于昂贵时。考虑下一个结构体有很多的字段。在方法内使用这个结构体做为值接收器需要拷贝整个结构体,这是很昂贵的。在这种情况下使用指针接收器,结构体不会被拷贝,只会传递一个指针到方法内部使用。
- 在其他的所有情况,值接收器都可以被使用。
孤儿规则🐶
下面的不允许,因为 int 类型和这个方法,不再同一个包里
func (a int) add(b int) {
}
解决方法
- 定义类型别名
type myInt int
func (a myInt) add(b myInt) myInt {
return a + b
}
- wrapper 包装
函数
匿名函数
func main() {
func(n string) {
fmt.Println("Welcome", n)
}("Gophers")
}
自定义函数类型
type add func(a int, b int) int
func main() {
var a add = func(a int, b int) int {
return a + b
}
s := a(5, 6)
fmt.Println("Sum", s)
}
高阶函数
// 接受函数
func simple(a func(a, b int) int) {
fmt.Println(a(60, 7))
}
// 返回函数
func simple() func(a, b int) int {
f := func(a, b int) int {
return a + b
}
return f
}
接口
类似于 dyn Train
type SalaryCalculator interface {
CalculateSalary() int
}
employees := []SalaryCalculator{pemp1, pemp2, cemp1}
接口的断言
- 类型断言
func assert(i interface{}) {
v, ok := i.(int)
fmt.Println(v, ok)
// 如果不是 int 类型,v 就会被赋为 T 的零值
}
func main() {
var s interface{} = 56
assert(s)
var i interface{} = "Steven Paul"
assert(i)
}
- switch type 注意:把变量传递到函数中后会自动转换类型到 interface,因此调用函数能行,但是下面直接 switch 就不行
- 回报错:a (variable of type int) is not an interface
func findType(i interface{}) {
switch i.(type) {
case string:
fmt.Printf("I am a string and my value is %s\n", i.(string))
case int:
fmt.Printf("I am an int and my value is %d\n", i.(int))
default:
fmt.Printf("Unknown type\n")
}
}
func main() {
a := 1
findType(a)
switch interface{}(a).(type) {
case string:
fmt.Printf("I am a string and my value is %s\n", interface{}(a).(string))
case int:
fmt.Printf("I am an int and my value is %d\n", interface{}(a).(int))
default:
fmt.Printf("Unknown type\n")
}
}
接口类型变量
声明一个变量是接口类型,那么这个变量可以被赋值为,任何实现了接口的类型
type Describer interface {
Describe()
}
type Person struct {
name string
age int
}
type Address struct {
state string
country string
}
现在还不能赋值,接下来为两个 struct 我们实现接口
为 person 实现 describe,使用值接受者,下面两种赋值都可以,也都能调用方法
func (p Person) Describe() { // 使用值接受者实现
fmt.Printf("%s is %d years old\n", p.name, p.age)
}
var d1 Describer
p1 := Person{"Sam", 25}
d1 = p1
d1.Describe()
p2 := Person{"James", 32}
d1 = &p2
d1.Describe()
为 Address 实现 describer,使用指针接受者,下面就比较特殊 d = a 不能直接赋值,如果是在结构体的方法中,下面的两种赋值都是可以的,但是在接口中不行
其原因是:对于使用指针接受者的方法,用一个指针或者一个可取得地址的值来调用都是合法的。但接口中存储的具体值(Concrete Value)并不能取到地址,因此在下面的例子中,对于编译器无法自动获取 a 的地址,于是程序报错。
func (a *Address) Describe() { // 使用指针接受者实现
fmt.Printf("State %s Country %s", a.state, a.country)
}
var d Describer
a := Address{"Washington", "USA"}
//d = a // 这是不合法的,会报错:Address does not implement Describer
d = &a // 这是合法的,Address 类型的指针实现了 Describer 接口
d.Describe()
接口可以嵌套
类似于匿名结构体的嵌套 一个结构体实现了 A,B,那就说它也实现了 C
type A interface {
foo()
}
type B interface {
bar() int
}
type C interface {
A
B
}
接口的零值
接口的零值是 nil,同时其底层值(Underlying Value)和具体类型(Concrete Type)都为 nil。调用方法会 panic
接口的坑
- 不能把 interface 赋值为别的类型
func main() { // 声明 a 变量,类型 int,初始值为 1 var a int = 1 // 声明 i 变量,类型为 interface{}, 初始值为 a,此时 i 的值变为 1 var i interface{} = a // 声明 b 变量,尝试赋值 i var b int = i } - 切片也不能再分
func main() { sli := []int{2, 3, 5, 7, 11, 13} var i interface{} i = sli g := i[1:3] fmt.Println(g) }
channel
特性
- go 的 channel 默认是双向的,既可以 send,也可以 recv
- channel 必须有发送端和接收端,否则就 panic
- make(chan int, n) n 表示缓冲区大小,可以省略,默认为 0
- 而对于无缓冲 channel,接受和发送都要在不同携程之间,不让两个人互相阻塞
- 对于有缓冲区 channel,在缓冲区大小内,两个不会互相阻塞,可以在同一协程内
- 如果超过缓冲区大小,就会 panic,所以超过缓冲区大小的还是必须在其他的协程中处理
- 缓冲区也有 len 和 cap 的概念
- 对于 rust,如果超出缓冲区大小 send 就会返回 Error
func sendData(sendch chan<- int) {
sendch <- 10
}
func main() {
cha1 := make(chan int)
go sendData(cha1)
fmt.Println(<-cha1)
}
单向 channel
// 声明参数是一个只能发送的 ch
func sendData(sendch chan<- int) {
sendch <- 10
}
func main() {
// 声明一个只能发送的 channel,下面使用它去接受就会 panic
// 如果声明为 chan int,下面的接受不会 panic,在 sendData 会被转换为只能发送的 channel,而 main 中的仍然是双向的
sendch := make(chan<- int)
go sendData(sendch)
fmt.Println(<-sendch)
}
关闭 channel
不能一直 send 或者一直 recv,处理完及时把一端 close 了
func producer(chnl chan int) {
for i := 0; i < 10; i++ {
chnl <- i
}
// 发送完成后,使用 send 函数显式关闭 channel
close(chnl)
}
func main() {
ch := make(chan int)
go producer(ch)
for {
// 通过 ok 判断 channel 是否关闭
v, ok := <-ch
if ok == false {
break
}
fmt.Println("Received ", v, ok)
}
}
waitGroup
等待一群协程结束
注意一定要使用指针
工作池
// 模拟耗时的计算
func calculate(number int) int {
time.Sleep(2 * time.Second)
return number
}
// 生产者,分发工作
func produceJobs(jobs chan<- Job, n int) {
for i := 0; i < n; i++ {
// fmt.Printf("sending %d \n", i)
jobs <- Job{
id: i,
number: i,
}
}
close(jobs)
}
// 消费者,接受工作,干完活就通知以下管理员
func consumeFunc(jobs <-chan Job, results chan<- int, wg *sync.WaitGroup) {
// 每个 worker 都在抢工作,真积极啊
for job := range jobs {
// fmt.Printf("id: %d\n", job.id)
results <- calculate(job.number)
}
wg.Done()
}
// 管理员,等待所有工人都通知他,每次被通知,计数器就减 1,当计数器为 0 是就不再阻塞
func consumeJobs(jobs <-chan Job, results chan<- int, worker_number int) {
// 等待一批 goroutine 结束,类似于 join
var wg sync.WaitGroup
// 为每一个工作开启一个 goroutine
for i := 0; i < worker_number; i++ {
wg.Add(1)
go consumeFunc(jobs, results, &wg)
}
wg.Wait() // 阻塞当前 goroutine 直到计数器归 0,所有 job 都应该做完了,result 应该也都发送出去了
close(results)
}
type Job struct {
id int
number int
}
func main() {
startTime := time.Now()
jobs := make(chan Job, 10)
results := make(chan int, 10)
// 发送 work, jobs send
go produceJobs(jobs, 100)
// jobs recv | results send
go consumeJobs(jobs, results, 50)
// results recv
a := 0
for res := range results {
a += res
}
fmt.Print("res: ", a)
endTime := time.Now()
diff := endTime.Sub(startTime)
fmt.Println("total time taken ", diff.Seconds(), "seconds")
}
select
用法挺普通
- channel 不限制 send/recv,只要是对 channel 的操作就行
- 如果有多个 channel 准备就绪,就随机选择一个执行
- 死锁与默认情况:如果 select 一直没有命中,就会触发死锁,导致 panic,空 select 一样也会导致 panic
- 可以准备一个 timeout chan,到时间就 send 作为超时信号
func main() {
ch := make(chan string)
select {
case <-ch:
default:
fmt.Println("default case executed")
}
}
并发
goroutine 不能保证并发安全,下面是一些解决方法
- 总体说来,当 Go 协程需要与其他协程通信时,可以使用 channel。而当只允许一个协程访问临界区时,可以使用 Mutex。
- 就我们上面解决的问题而言,我更倾向于使用 Mutex,因为该问题并不需要协程间的通信。所以 Mutex 是很自然的选择。
mutex
func aa(wg *sync.WaitGroup, m *sync.Mutex) {
m.Lock()
x += 1
m.Unlock()
wg.Done()
}
func main() {
var wg sync.WaitGroup
var m sync.Mutex
for i := 0; i < 1000; i++ {
wg.Add(1)
go aa(&wg, &m)
}
wg.Wait()
fmt.Print(x)
}
channel
使用缓冲为 1 的 channel 实现
func aa(wg *sync.WaitGroup, ch chan bool) {
ch <- true
x += 1
<-ch
wg.Done()
}
func main() {
startTime := time.Now()
var wg sync.WaitGroup
var ch = make(chan bool, 1)
for i := 0; i < 1000; i++ {
wg.Add(1)
go aa(&wg, ch)
}
wg.Wait()
fmt.Print(x)
}
defer
实参求值
当执行 defer 语句的时候,就会对延迟函数的实参进行求值。
func printA(a int) {
fmt.Println("value of a in deferred function", a)
}
func main() {
a := 5
defer printA(a)
a = 10
}
// value of a in deferred function 5
defer 栈
当一个函数内多次调用 defer 时,Go 会把 defer 调用放入到一个栈中,随后按照后进先出(Last In First Out, LIFO)的顺序执行。
下面的程序,使用 defer 栈,将一个字符串逆序打印。
func main() {
name := "Naveen"
for _, v := range []rune(name) {
defer fmt.Printf("%c", v)
}
}
// 倒叙输出:neevaN
defer 在 return 后执行
import "fmt"
var name string = "go"
func myfunc() string {
defer func() {
name = "python"
}()
fmt.Printf("myfunc 函数里的 name:%s\n", name) // go
return name
}
func main() {
myname := myfunc()
fmt.Printf("main 函数里的 name: %s\n", name) // python
fmt.Println("main 函数里的 myname: ", myname) // go
}
使用场景
func (r rect) area(wg *sync.WaitGroup) {
// defer wg.Done() // 代替下面的 3 个 return 中的 wg.Done()
if r.length < 0 {
fmt.Printf("rect %v's length should be greater than zero\n", r)
wg.Done()
return
}
if r.width < 0 {
fmt.Printf("rect %v's width should be greater than zero\n", r)
wg.Done()
return
}
area := r.length * r.width
fmt.Printf("rect %v's area %d\n", r, area)
wg.Done()
}
错误处理
错误接口
在标准库里的定义
type error interface {
Error() string
}
open 函数的设计
type PathError struct {
Op string
Path string
Err error
}
func (e *PathError) Error() string { return e.Op + " " + e.Path + ": " + e.Err.Error() }
错误类型断言
通过类型断言拿到错误信息
func main() {
f, err := os.Open("/test.txt")
if err, ok := err.(*os.PathError); ok {
fmt.Println("File at path", err.Path, "failed to open")
return
}
fmt.Println(f.Name(), "opened successfully")
}
子错误类型
type DNSError struct {
...
}
func (e *DNSError) Error() string {
...
}
func (e *DNSError) Timeout() bool {
...
}
func (e *DNSError) Temporary() bool {
...
}
func main() {
addr, err := net.LookupHost("golangbot123.com")
if err, ok := err.(*net.DNSError); ok {
if err.Timeout() {
fmt.Println("operation timed out")
} else if err.Temporary() {
fmt.Println("temporary error")
} else {
fmt.Println("generic error: ", err)
}
return
}
fmt.Println(addr)
}
panic 和 recover
下面使用 recover 去恢复 panic
- 注意:Go 协程中调用 recover 才管用。recover 不能恢复一个不同协程的 panic。
func recoverName() {
if r := recover(); r!= nil {
fmt.Println("recovered from ", r)
}
}
func fullName(firstName *string, lastName *string) {
defer recoverName()
if firstName == nil {
panic("runtime error: first name cannot be nil")
}
if lastName == nil {
panic("runtime error: last name cannot be nil")
}
fmt.Printf("%s %s\n", *firstName, *lastName)
fmt.Println("returned normally from fullName")
}
恢复后获得堆栈
import (
"runtime/debug"
)
func r() {
if r := recover(); r != nil {
fmt.Println("Recovered", r)
debug.PrintStack()
}
}
反射
基础
type order struct {
ordId int
customerId int
}
func play(q interface{}) {
t := reflect.TypeOf(q)
k := t.Kind()
v := reflect.ValueOf(q)
fieldsNum := v.NumField()
fmt.Println("Type: ", t, "Kind: ", k)
fmt.Println("Value: ", v, "FieldNum: ", fieldsNum)
for i := 0; i < fieldsNum; i++ {
fmt.Println(t.Field(i).Name, v.Field(i).Type(), v.Field(i))
}
}
func createQuery(q interface{}) {
// 拿到类型
if reflect.TypeOf(q).Kind() != reflect.Struct {
return
}
// 拿到类型名称
t := reflect.TypeOf(q).Name()
query := fmt.Sprintf("insert into %s values(", t)
// 拿到值
v := reflect.ValueOf(q)
// 拿到字段数量
for i := 0; i < v.NumField(); i++ {
// 拿到字段类型,字段名称,字段值
switch v.Field(i).Kind() {
case reflect.Int:
if i == 0 {
query = fmt.Sprintf("%s%d", query, v.Field(i).Int())
} else {
query = fmt.Sprintf("%s, %d", query, v.Field(i).Int())
}
case reflect.String:
if i == 0 {
query = fmt.Sprintf("%s\"%s\"", query, v.Field(i).String())
} else {
query = fmt.Sprintf("%s, \"%s\"", query, v.Field(i).String())
}
default:
fmt.Println("unsupported field type")
return
}
}
query = fmt.Sprintf("%s)", query)
fmt.Println(query)
return
}
func main() {
o := order{
ordId: 456,
customerId: 56,
}
play(o)
println("----------------------------------------")
createQuery(o)
var a int = 1
b := reflect.ValueOf(a).String()
fmt.Println(reflect.TypeOf(b))
}
修改类型
func main() {
var age interface{} = 25
v := reflect.ValueOf(age)
// 从反射对象到接口变量
i := v.Interface().(int)
}
可写性
func main() {
var name string = "Go 编程时光"
v1 := reflect.ValueOf(&name)
fmt.Println("v1 可写性为:", v1.CanSet())
v2 := v1.Elem()
fmt.Println("v2 可写性为:", v2.CanSet())
}
进阶
变量
make
make 函数创建 slice、map 或 chan 类型变量
和 new 的区别
-
new:为所有的类型分配内存,并初始化为零值,返回指针。
-
make:只能为 slice,map,chan 分配内存,并初始化,返回的是类型 (指针)。因为这三个本身就是引用类型
-
slice、map 和 chan 是 Go 中的引用类型,它们的创建和初始化,一般使用 make。特别的,chan 只能用 make。slice 和 map 还可以简单的方式:
slice := []int{0, 0}
m := map[string]int{}
匿名变量
- 不分配内存,不占用内存空间
浮点数
浮点数转二进制时丢失了精度,计算完再转回十进制时和理论结果不同。
- f32: 1 8
- f64: 1 11
作用域
分类
- 内置作用域:不需要自己声明,所有的关键字和内置类型、函数都拥有全局作用域
- 包级作用域:必須函数外声明,在该包内的所有文件都可以访问
- 文件级作用域:不需要声明,导入即可。一个文件中通过 import 导入的包名,只在该文件内可用
- 局部作用域:在自己的语句块内声明,包括函数,for、if 等语句块,或自定义的 {} 语句块形成的作用域,只在自己的局部作用域内可用
作用规则
- 低层作用域,可以访问高层作用域
- 同一层级的作用域,是相互隔离的
- 低层作用域里声明的变量,会覆盖高层作用域里声明的变量
动态作用域
下面的 bash 脚本中,func02 在 func01 内部可以访问到 value,但在 func01 外面不能,属于动态作用域
#!/bin/bash
func01() {
local value=1
func02
}
func02() {
echo "func02 sees value as ${value}"
}
# 执行函数
func01
func02
协程池
type Pool struct {
work chan func() // 任务
sem chan struct{} // 使用缓冲区大小控制工人数量
}
func New(size int) *Pool {
return &Pool{
work: make(chan func()),
sem: make(chan struct{}, size),
}
}
func (p *Pool) worker(task func()) {
defer func() { <-p.sem }()
for {
task()
task = <-p.work
}
}
func (p *Pool) NewTask(task func()) {
// 第一次加新任务时,work 缓冲区大小为 0,发出去也没人接受,所以一定会走第二个
// 相当于找到了第一个工人处理任务,worker 本身是个 for 循环,它处理完第一个任务后会继续接受新任务
// 第二次加入时,就被第一个工人处理了,
// 如果第三个加入,因为 sem 缓冲区大小的限制,不会继续产生新的 worker
select {
case p.work <- task:
case p.sem <- struct{}{}:
go p.worker(task)
}
}
func main() {
pool := New(2)
for i := 0; i < 5; i++ {
pool.NewTask(func() {
time.Sleep(1 * time.Second)
fmt.Println(time.Now())
})
}
time.Sleep(4 * time.Second)
}
动态类型
接口分为两种iface和eface
所有的变量都实现了空接口 (eface)
// 定义静态类型
i := (int)(25)
i = "Go 编程时光" // 会报错
// 定义动态类型
i := (interface{})(25)
var i interface{}
i = 18
i = "Go 编程时光" // 上面三种都行,不会报错
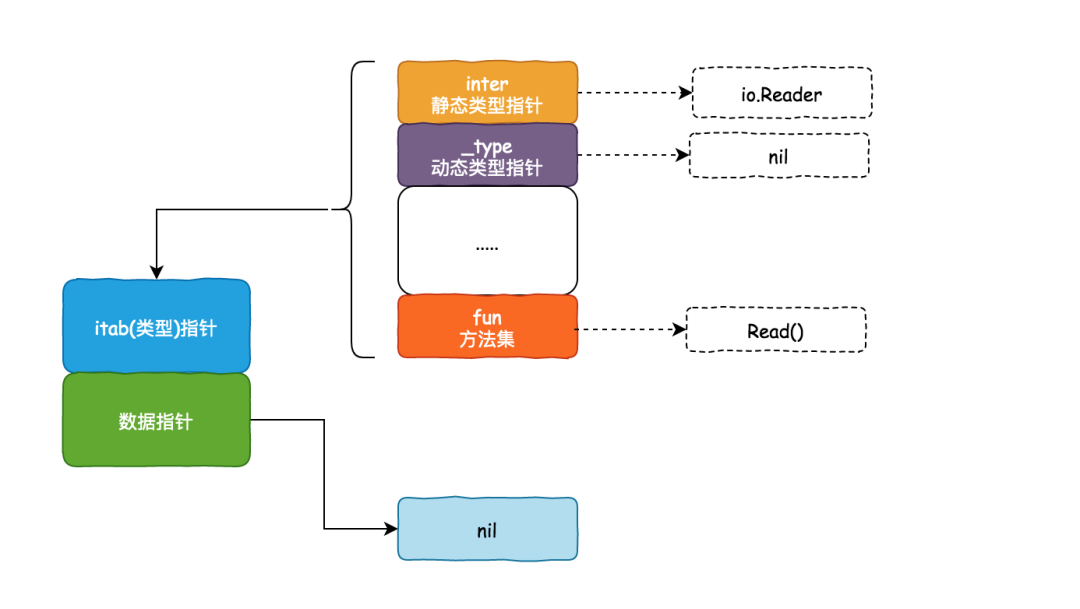
var reader io.Reader
tty, err := os.OpenFile("/dev/tty", os.O_RDWR, 0)
if err != nil {
return nil, err
}
reader = tty
第一行代码结束后,reader 的静态类型为io.Reader还没有动态类型
 被赋值为 tty 后,reader 的动态类型变为
被赋值为 tty 后,reader 的动态类型变为*os.File
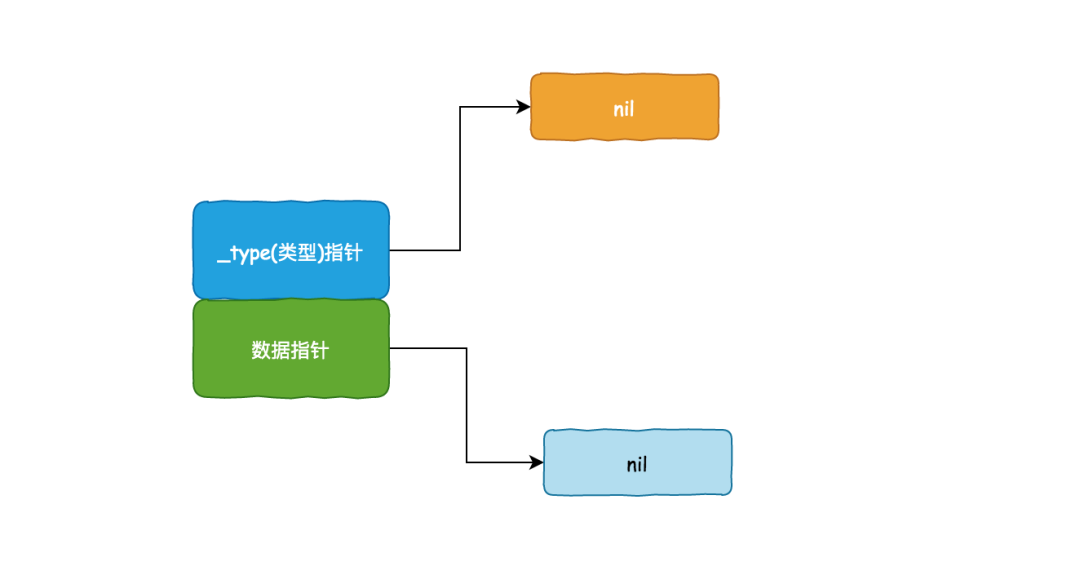
//不带函数的 interface
var empty interface{}
tty, err := os.OpenFile("/dev/tty", os.O_RDWR, 0)
if err != nil {
return nil, err
}
empty = tty
刚开始 empty 是 eface,_type为 nil
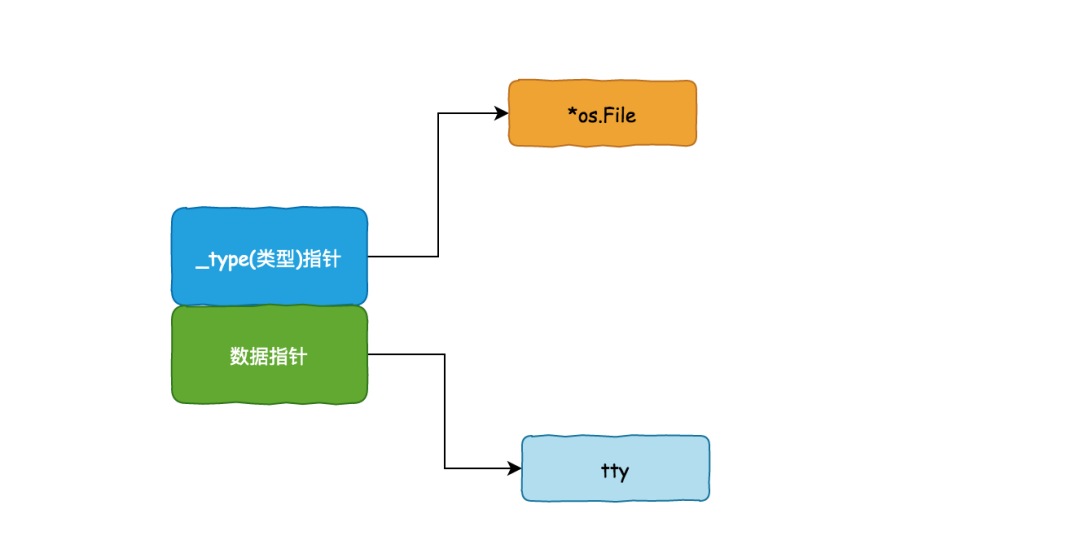
 被赋值后,
被赋值后,_type的静态类型为*os.File
导入
导入方式:
- 绝对导入:从
$GOPATH/src或$GOROOT或者$GOPATH/pkg/mod目录下搜索包并导入 - 相对导入:从当前目录中搜索包并开始导入。就像下面这样
注意:
- 导入时,是按照目录导入。导入目录后,可以使用这个目录下的所有包。
- 只要不是
.或..开头,全都是绝对路径
context
当一个 goutine 开启后,只能通过 channel 的通知实现管理,使用 context 更方便了
当你把 Context 传递给多个 goroutine 使用时,只要执行一次 cancel 操作,所有的 goroutine 就可以收到 取消的信号,Context 是线程安全的,可以放心地在多个 goroutine 中使用。
context 创建依赖于 4 个函数
- withCancel 最普通,只能使用 cancel 去结束
- withDeadline 和 WithDeadline 会在超时后自动 cancel,传递的是绝对时间和相对时间
- withValue 能够携带一些键值对 (键应该是可比的,值必须是线程安全的)
func WithCancel(parent Context) (ctx Context, cancel CancelFunc)
func WithDeadline(parent Context, deadline time.Time) (Context, CancelFunc)
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc)
func WithValue(parent Context, key, val interface{}) Context
func monitor(ctx context.Context, number int) {
for {
select {
case <- ctx.Done():
fmt.Printf("监控器%v,监控结束。\n", number)
return
default:
fmt.Printf("监控器%v,正在监控中...\n", number)
time.Sleep(2 * time.Second)
}
}
}
func main() {
ctx01, cancel := context.WithCancel(context.Background())
ctx02, cancel := context.WithDeadline(ctx01, time.Now().Add(1 * time.Second))
defer cancel()
for i :=1 ; i <= 5; i++ {
go monitor(ctx02, i)
}
time.Sleep(5 * time.Second)
if ctx02.Err() != nil {
fmt.Println("监控器取消的原因:", ctx02.Err())
}
fmt.Println("主程序退出!!")
}