协程与异步
协程的 C 实现
linux
下在头文件ucontext.h提供了getcontext(),setcontext(),makecontext(),swapcontext()四个函数和mcontext_t 和 ucontext_t结构体。
这 4 个函数能够实现保存,获取,设置,切换上下文,是协程实现的核心,也是 yield 的核心
结构体则保留了协程的 id,运行堆栈等信息
-
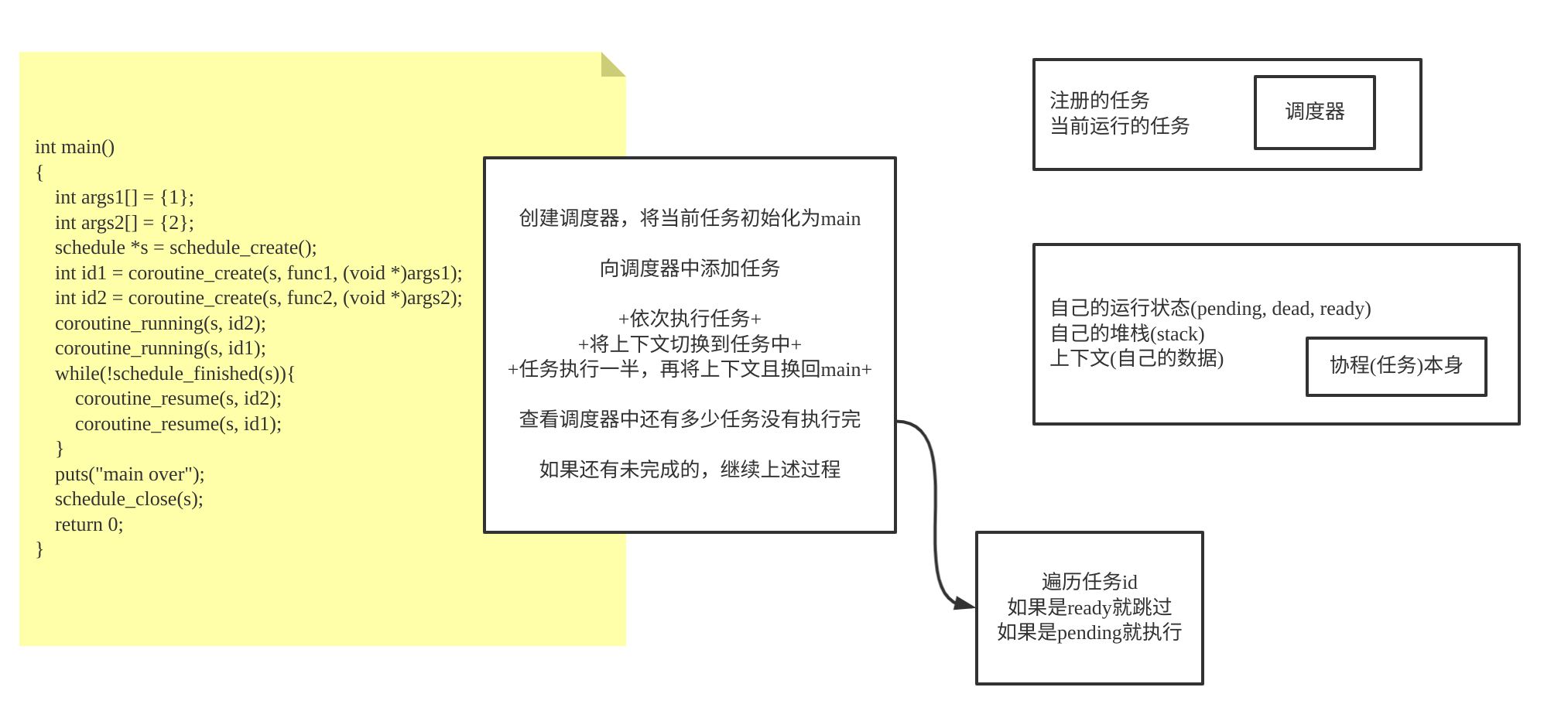
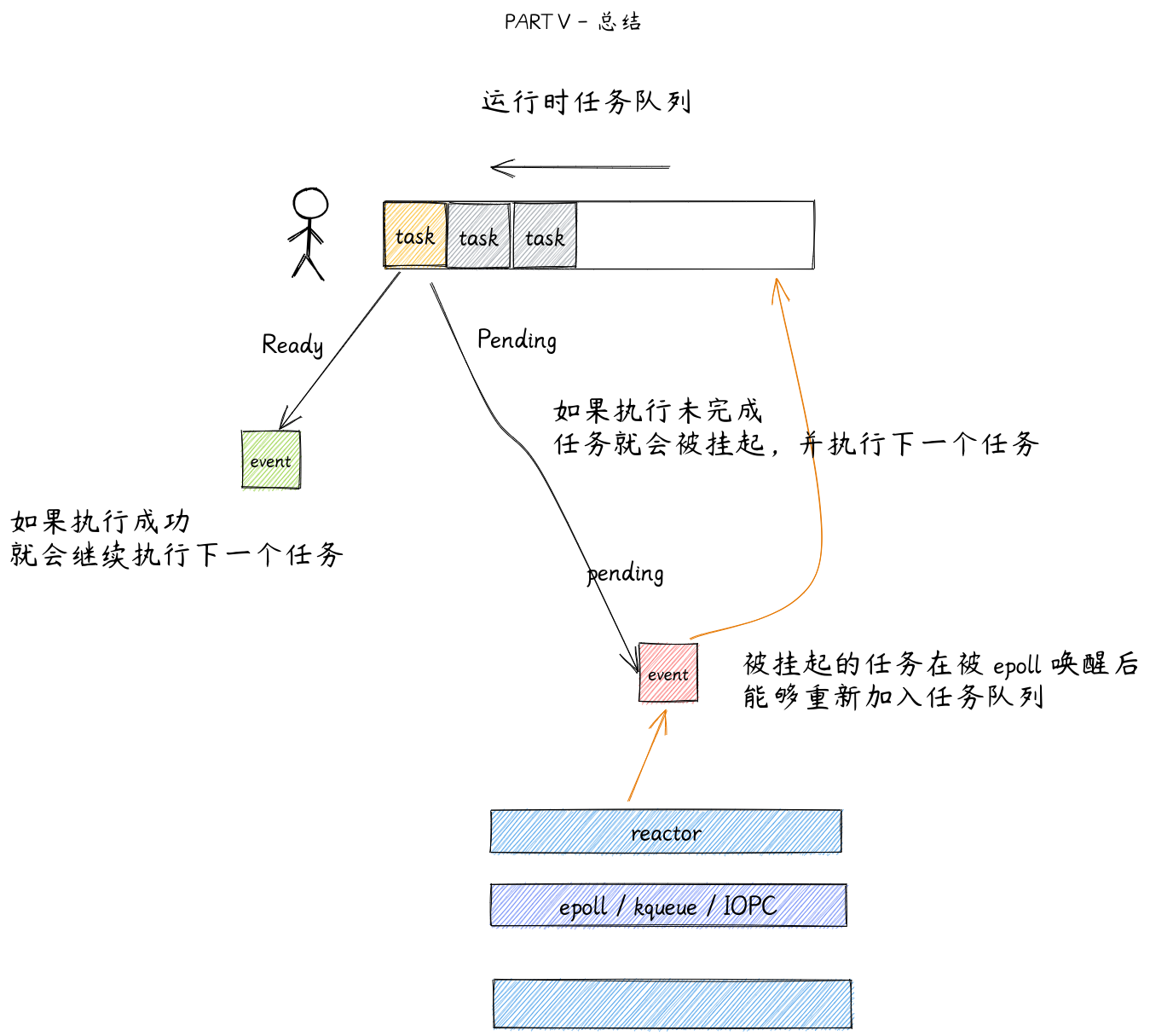
不同协程保存在队列中,由一个调度器进行推进各个协程
-
调度器会依次执行每个协程,每当某一个协程进行了 yield 操作 (
swapcontext()), 调度器就会切换到另一个协程的上下文,继续推进 -
当所有协程都执行完成,就结束
下面的图片是阅读了上面代码后的整理
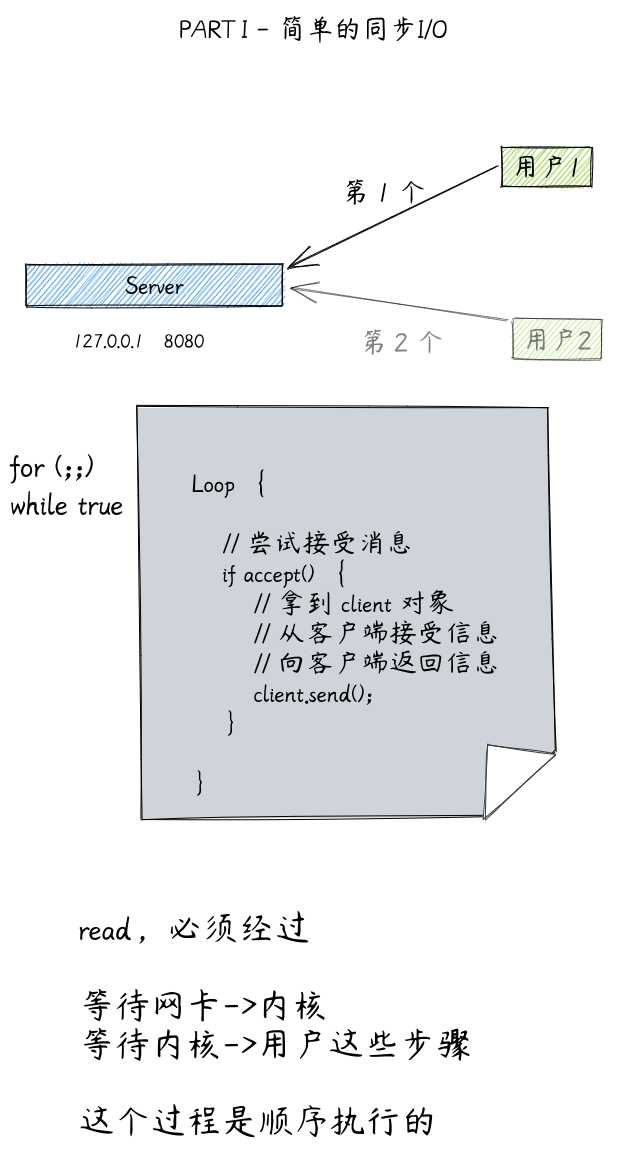
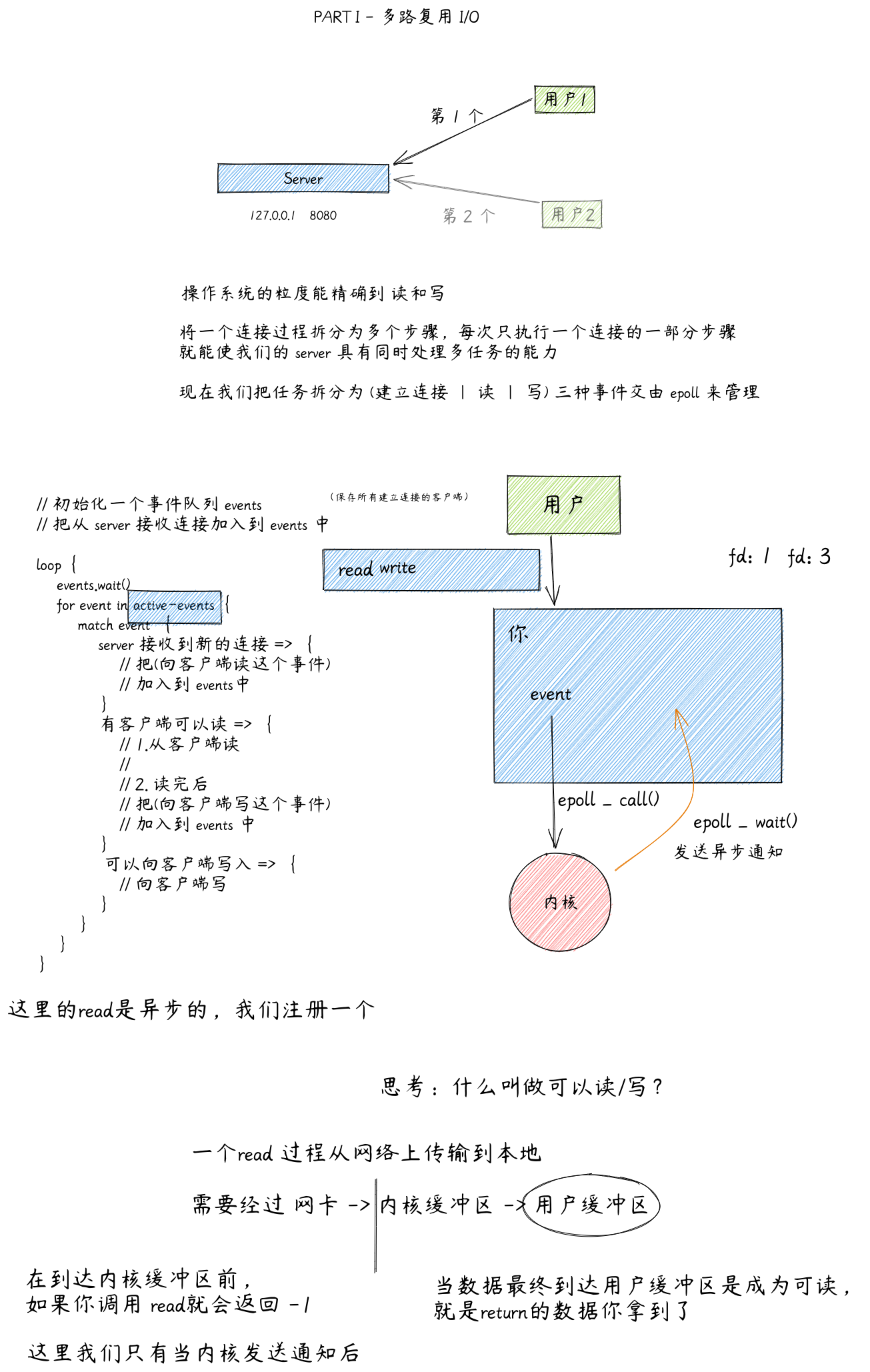
Reactor 机制
异步

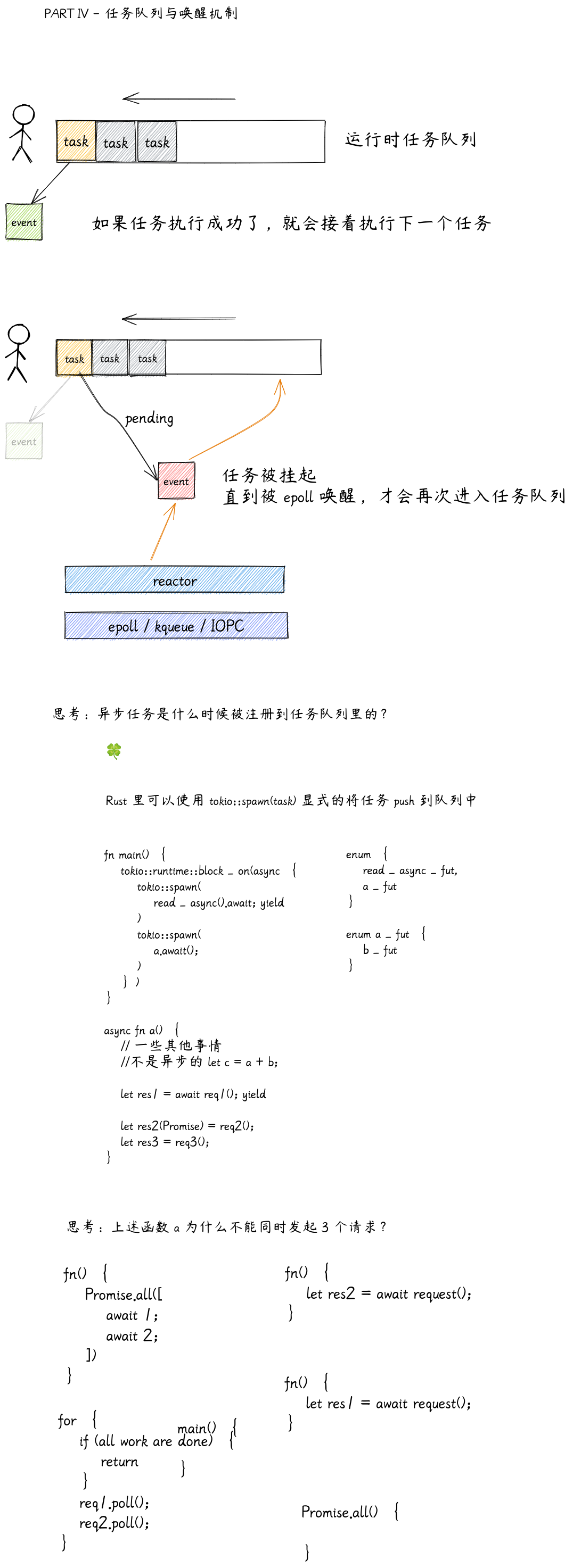

Rust 异步原理
Future 特征
trait Future {
type Output;
fn poll(self: Pin<&mut Self>, cx: &mut Context)
-> Poll<Self::Output>;
}
enum Poll<T> {
Pending,
Ready(T),
}
编译异步代码时发生了什么
下面是一段异步代码,它向 server 异步请求了一段数据,接着把结果进行格式转换,最后将数据通过 stream 异步发送出去:
async fn handle_request(
server: &RpcServer,
mut stream: TcpStream,
id: i32,
) -> impl Future<Output = ()> {
let row = get_row(&server, id).await;
let encoded = json::encode(&row);
stream.write_all(encoded.as_bytes()).await;
}
编译器会为为这个异步函数创建一个对象,能够表现当前异步操作的状态:
struct RequestHandler {
server: &RpcServer,
stream: TcpStream,
id: i32,
}
接着需要为它实现 Future 特征
在 poll 方法内部就是一个状态机,每次调用 poll 就会尝试推进异步任务,并根据状态作出对应的活动
impl Future for RequestHandler {
type Output = ();
fn poll(&mut self, cx: &mut Context) -> Pool<()> {
loop {
match self.state {
...
}
}
}
}
状态机
现在我们要为它手动编写一个状态机
首先为了能够跟踪请求的状态,我们要为结构体添加一个 state 字段:
struct RequestHandler {
...
state: RHState
}
接着 match 状态,并执行对应的行为。
- 第一个状态是
Unpolled,此时这个异步函数还没有被 poll 过,它要进行一些初始化操作 - 第二个状态是
GettingRow,我们等待从数据库获取数据 - 第三个状态是
Writing,等待写入 tcpstream - 第四个状态是
Ready,完成并准备返回结果
Unpolled
我们首先调用 get_row 函数,因为它是异步的,所以并不会立即执行,而是返回一个 future 对象。
match self.state {
Unpolled => {
self.row_fut = Some(get_row(&self.server, self.id));
self.state = GettingRow
}
}
同时我们在结构体中添加一个字段保存这个 future
struct RequestHandler {
...
row_fut: Option<RowGet>,
}
GettingRow
第二阶段我们就要开始尝试推进异步任务,如果任务完成的话就把需要的变量赋值到结构体,并初始化下一个 future 任务,推进状态。
match self.state {
...
GettingRow => {
match self.row_fut.unwrap().poll(cx) {
Poll::Pending => return Poll::Pending,
Poll::Ready(row) => {
self.row_fut = None;
self.encoded = json::encode(row);
self.write_fut = Some(self.stream.write_all(
self.encoded.as_bytes()));
self.state = Writing;
}
}
}
}
结构体需要添加 encoded 字段,和下一个 future 任务:
struct RequestHandler {
...
encoded: String,
write_fut: Option<WriteAll>,
}
Writing
第三阶段任务很简单,如果写入完成就推进状态:
match self.state {
...
Writing => {
match self.row_fut.unwrap().poll(cx) {
Poll::Pending => return Poll::Pending,
Poll::Ready(_) => self.state = Ready,
}
}
}
Ready
最后就返回异步函数真正的的运行结果
match self.state {
...
Ready => return Poll::Ready(())
}

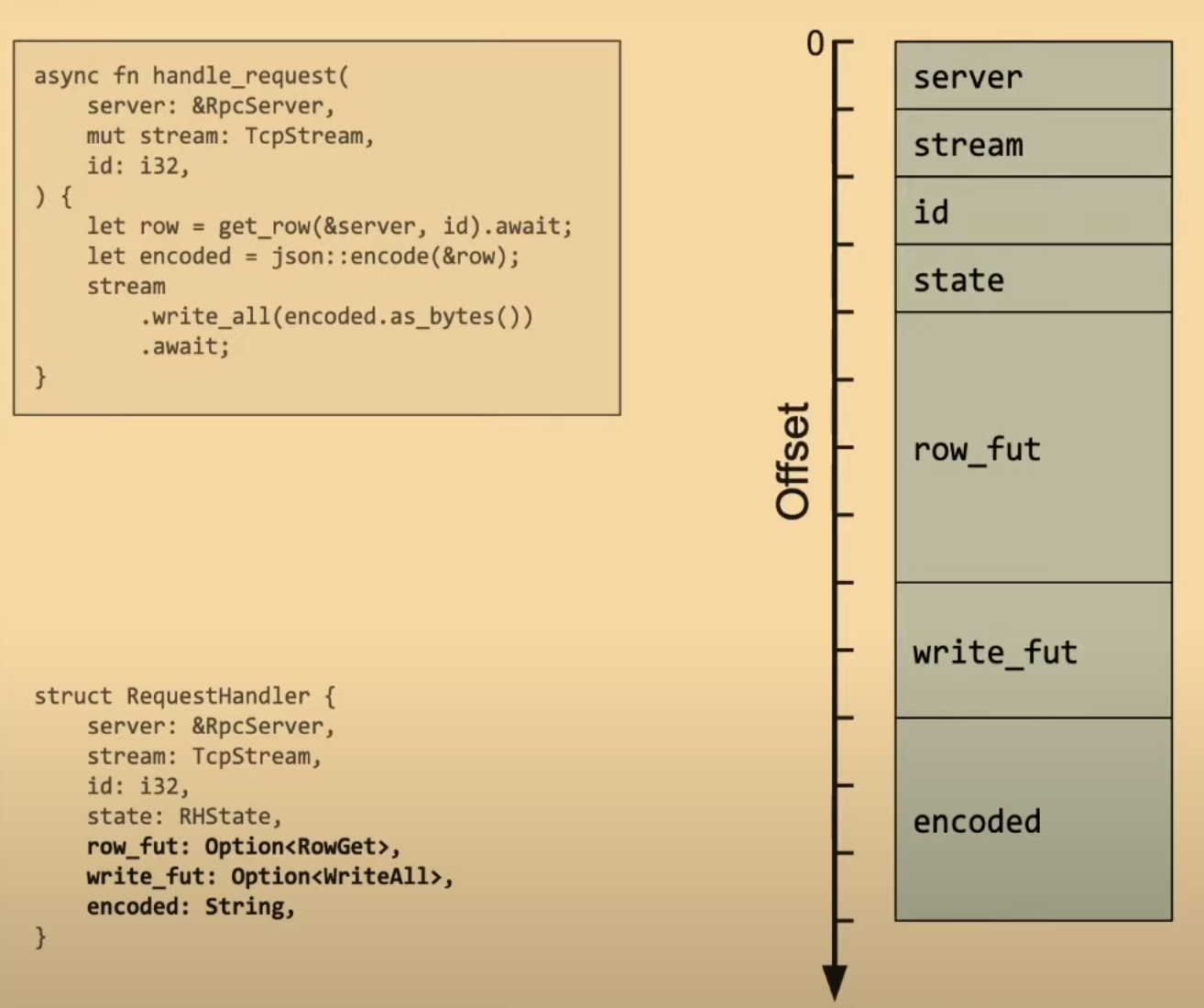
使用 enum 节省内存
使用 struct 保存异步任务时,我们不得不为所有变量和异步任务都提前分配好内存。
下图是这个结构体的内存布局
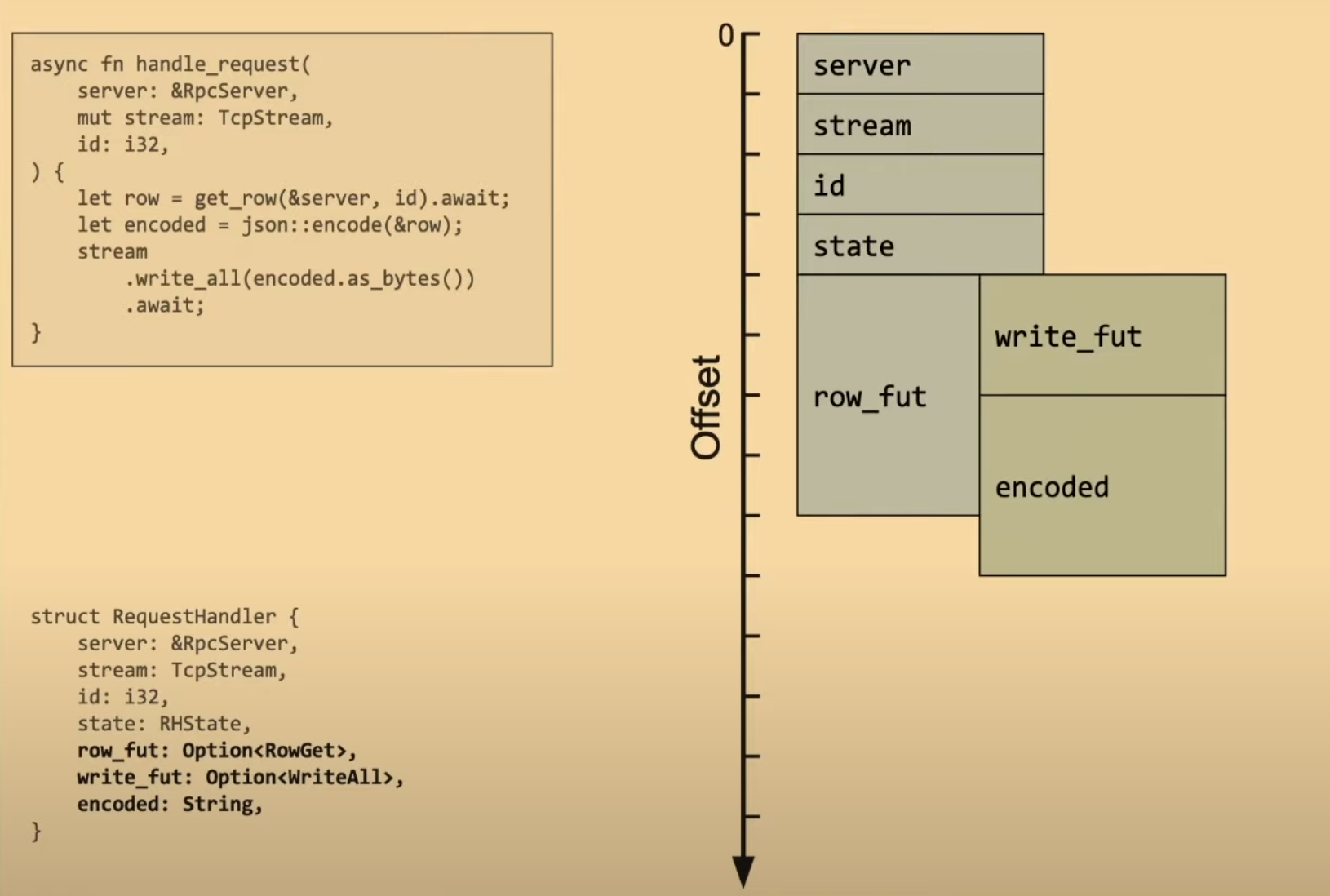
 如果两个异步任务不会同时运行,那么这两个阶段的异步任务应该能够复用同一块内存,就像下图里那样:
如果两个异步任务不会同时运行,那么这两个阶段的异步任务应该能够复用同一块内存,就像下图里那样:
 假设异步任务里面还嵌套着其他的异步任务,那么这个结构体就会变得更大,嵌套层级越深,内存占用就越大
假设异步任务里面还嵌套着其他的异步任务,那么这个结构体就会变得更大,嵌套层级越深,内存占用就越大
性能
drop
async fn do_stuff(context: Arc<Context>) {
info!("running foo with context {}", context);
foo().await;
} // <- std::mem::drop(context);
对于上面的异步函数有一个小小的性能问题,每当一个变量超出作用域时,Rust 都会隐式的在函数末尾插入 drop,所以直到函数运行结束 context 变量才会被释放。但是我们在打完日志之后就不需要 context 了,没必要等到 foo 执行完在释放掉 context
其中一个解决方法时将 context 移动到函数的内部作用域:
async fn do_stuff(context: Arc<Context>) {
{
let context = context;
info!("running foo with context {}", context);
} // <- std::mem::drop(context);
foo().await;
}
drop 会被移动到内部作用域的末尾,但是这样依然不完美。future 在被 poll 之前什么都不会做,函数开始的任何一行都不会执行,所以在没有 poll 时我们还是一只持有着 context 变量。
解决问题的最好办法实际上是脱糖:
fn do_stuff(context: Arc<Context>) -> impl Future<Output = ()> {
info!("running foo with context {}", context);
async {
foo().await;
}
}
这样 context 根本就不会被保存在我们的状态机里,我们也永远不会持有对 context 的引用
大数据
另一个注意的点是,当你在 await 一个非常大的临时变量或者表达式
struct Big([u8; 1024]);
impl Drop for Big { /* print "GOODBYE" */ }
async fn foo(x: usize) -> usize { /* ... */ }
async fn bar() -> usize {
let result = foo(Big::new().0.len()).await;
result
}
如果你尝试打印 bar 的大小:
fn main() {
dng!(std::mem::size_of_val(&bar())); // 1024
}
结果会非常大,那是因为 Rust 会在状态机里插入 Big 的副本。原因是 只要你在语句中创建临时变量,都会在语句的最后调用该临时变量的 drop
函数。因此在 .await 运行后,drop 函数里的打印会执行。
异步函数里的临时变量都会存活到 .await 之后。
解决方法:让获取 len 和 调用 foo 方法之间插入一个分号
async fn bar() -> usize {
let len = Big::new().0.len();
let result = foo(len).await;
result
}
当然,你也可以写成这样:
async fn bar() -> usize {
let fut = foo(Big::new().0.len());
let result = fut.await;
result
}
因为我们不再需要在状态机中保存 Big 的副本,所以现在 bar 就小的多了:
fn main() {
dng!(std::mem::size_of_val(&bar())); // 24
}
如果你没有为 Big 实现 Drop,编译器应该为此做出一些优化,不过这个现在不谈